
向千万并发连接前进
去年最后一天的最后几个小时,我们一个数据中心的数据库再次因为Burst Balance耗尽导致整站性能缓慢,将该数据库硬盘从GP2升级至GP3后,性能瞬间恢复。该特性刚上线不久,算是救了我们一命。
元旦假期过后,SPM警告我们:不能再这么省钱,用户体验要紧。
我们计划今年要在架构上:(上半年要)支持千万并发,(下半年要)支持千万用户。
我自己心想:怎样能更省点。
中国新年结束,我们开始进行架构变更,4月中旬结束。我们达成架构上支持千万并发的同时,给了用户更好的体验,且整体成本再次下降,本文会围绕如何达成这些目标来简要描述。
数据库 - 问题根源
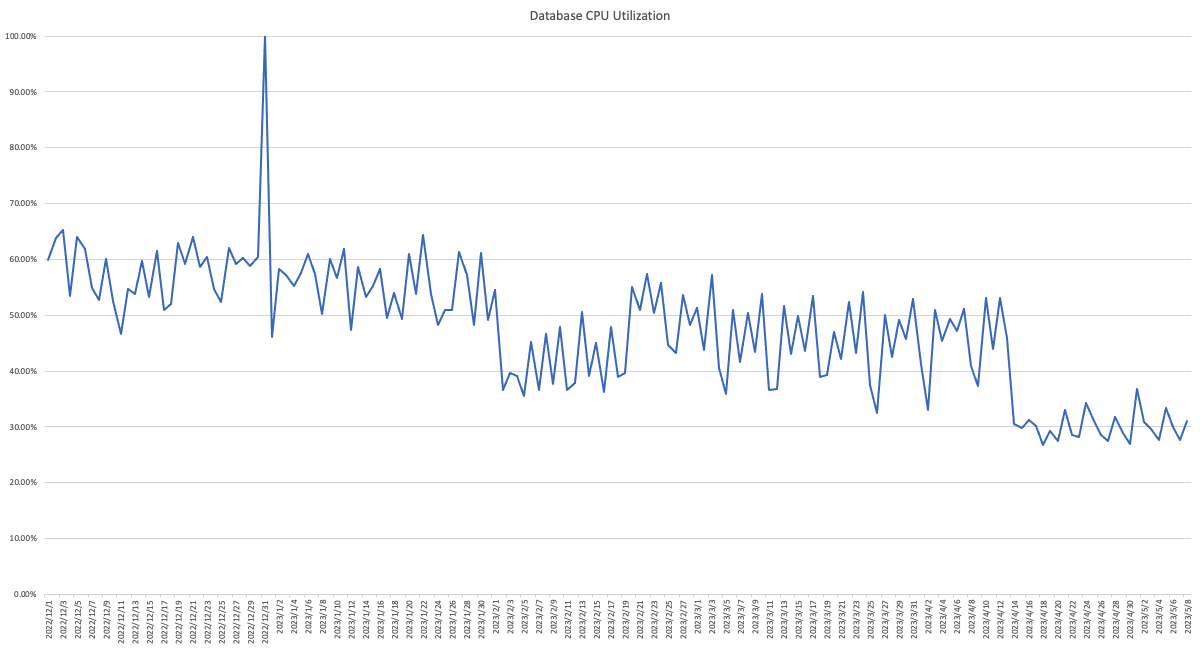
还是两年前数据库出问题的那张表。相较于上次出问题时的业务量,这次增涨了数十倍,而数据库规格仍未变化,仍然是4核16G内存。但我们有计划将数据库CPU架构从x86升级至ARM。
CPU架构升级带来的性能变化
此次升级为平移升级,规格同为4核16G内存,CPU从Intel更换为Graviton,AWS称有最多35%性能和52%性价比提升,但我们感觉提升并不大。
2月初我们进行了应用上的大幅优化,用数百万缓存Key减缓数据库的扫表压力,直接将数据库CPU峰值占用从60%压到了40%。之后业务增长带来了更大的压力,接着中间件升级的机会,我们更换了更高效查询语句,并去除占用很多资源的无效索引,忙时平均占用又从50%下降到了30%。改动效果拔群,减轻数据库压力,同时也减轻很多心理压力,我们有更多的时间喘息,思考,决策,以便做更大规模的改动。从这点上看,切换数据库CPU架构带来的性能效果与优化结果相比不太明显。
提升不明显,但还要做数据库CPU架构改动
更改CPU架构,可获得更优CPU性能,还能降低费用。如弗吉尼亚多可用区部署的m5.xlarge数据库升级为m6g.xlarge,即使性能提升不大,一年全额预付费用会从3729美元下降至3330美元。
接下来的架构改动还会再次大幅降低数据库的负载,当前数据库规格支撑今后三年的业务量绰绰有余,因此我们敢全额预付三年数据库实例,总费用6717美元,每年2239美元,费用下降了40%。
对数据库性能有自信
将数据库硬盘类型从GP2升级至GP3后,IOPS最繁忙的那张表有非常优异的性能。
假定数据库硬盘是200G的GP2,提供750 IOPS的基准性能,超过750 IOPS时会开始用到Burst Balance。而最基础的GP3硬盘,默认提供3000 IOPS基准性能,与GP2相比有更高的预置IOPS,不超过性能峰值时性能稳定。而硬盘升至400G时,GP3预置12000 IOPS和500MiB/s的吞吐,同样容量同样价格,GP3的IOPS性能至少是GP2的4倍。更快速磁盘IO能减少数据库的IO Wait,CPU占用率也会下降。
| 类型 | 容量 | 预置IOPS | 突发IOPS | 预置吞吐(MiB/s) | 突发吞吐(MiB/s) | 价格(USD/730小时) |
|---|---|---|---|---|---|---|
| GP2 | 200G | 600 | 3000 | 128 | 250 | 46 |
| GP2 | 400G | 800 | 3000 | 128 | 250 | 92 |
| GP3 | 200G | 3000 | / | 125 | / | 46 |
| GP3 | 400G | 12000 | / | 500 | / | 92 |
效果很不错,于是我们把在数据库上获得的经验,应用到了其他服务上。
经验应用到了其他地方
实例硬盘从GP2升级到GP3,预置IOPS性能已经相当出色,在这基础上还可定制更高IOPS和吞吐,降低费用,或维持费用不变的同时提升性能。如下是GP2与GP3的硬盘比较:
| 类型 | 容量 | 预置IOPS | 突发IOPS | 预置吞吐(MiB/s) | 突发吞吐(MiB/s) | 价格(USD/730小时) |
|---|---|---|---|---|---|---|
| GP2 | 10G | 30 | 3000 | 128-250 | 250 | 10 |
| GP2 | 1000G | 3000 | 16000 | 128-250 | 250 | 100 |
| GP3 | 10G | 3000 | / | 125 | / | 8 |
| GP3 | 1000G | 3000 | / | 125 | / | 80 |
| GP3 | 1000G | 3000 | / | 625 | / | 100 |
| GP3 | 1000G | 7000 | / | 125 | / | 100 |
| GP3 | 1000G | 5000 | / | 375 | / | 100 |
| GP3 | 1250G | 3000 | / | 125 | / | 100 |
| GP3 | 1100G | 4000 | / | 300 | / | 100 |
GP3硬盘性能可以在容量、IOPS、吞吐三者中取舍。同样价格,GP3甚至都可以超过GP2所有基准。而我们的大部分GP2硬盘容量低于1000G,切换至GP3立即提升性能且费用下降20%。再根据具体业务场景分配IOPS或吞吐,如不断写入的记录表需要很多的IOPS去年我们将ClickHouse机器从平均每秒2K IOPS优化至每秒2 IOPS,而日志中心在收录和检索日志上更依赖吞吐。
除此之外,为了追求更高的性价比,我们在逐步淘汰X86实例,慢慢切换至ARM实例上。因此,我们做好应用、中间件的升级、优化、适配和测试,以期发挥最佳性能。
应用上进行组件升级和性能优化
组件升级
去年年中我们计划将应用基础架构升级至Spring Boot 3,运行环境也连带升级到了Java 17。
Spring Boot 3.0.0版本释出第一天,我们立即进行适配,将过期、无人维护的组件剔除。需求不停,我们要不断将主干分支上的代码合并至适配分支,而要适配新版本中间件,又要不断在适配分支上进行迭代。所有瞻前顾后,都是确保所有代码正常编译、应用正常运行。
等待了漫长的4个月后,我们在生产上逐步更换运行容器,并对运行的指标十分满意。举一个应用的一个指标:JVM GC停顿时长。
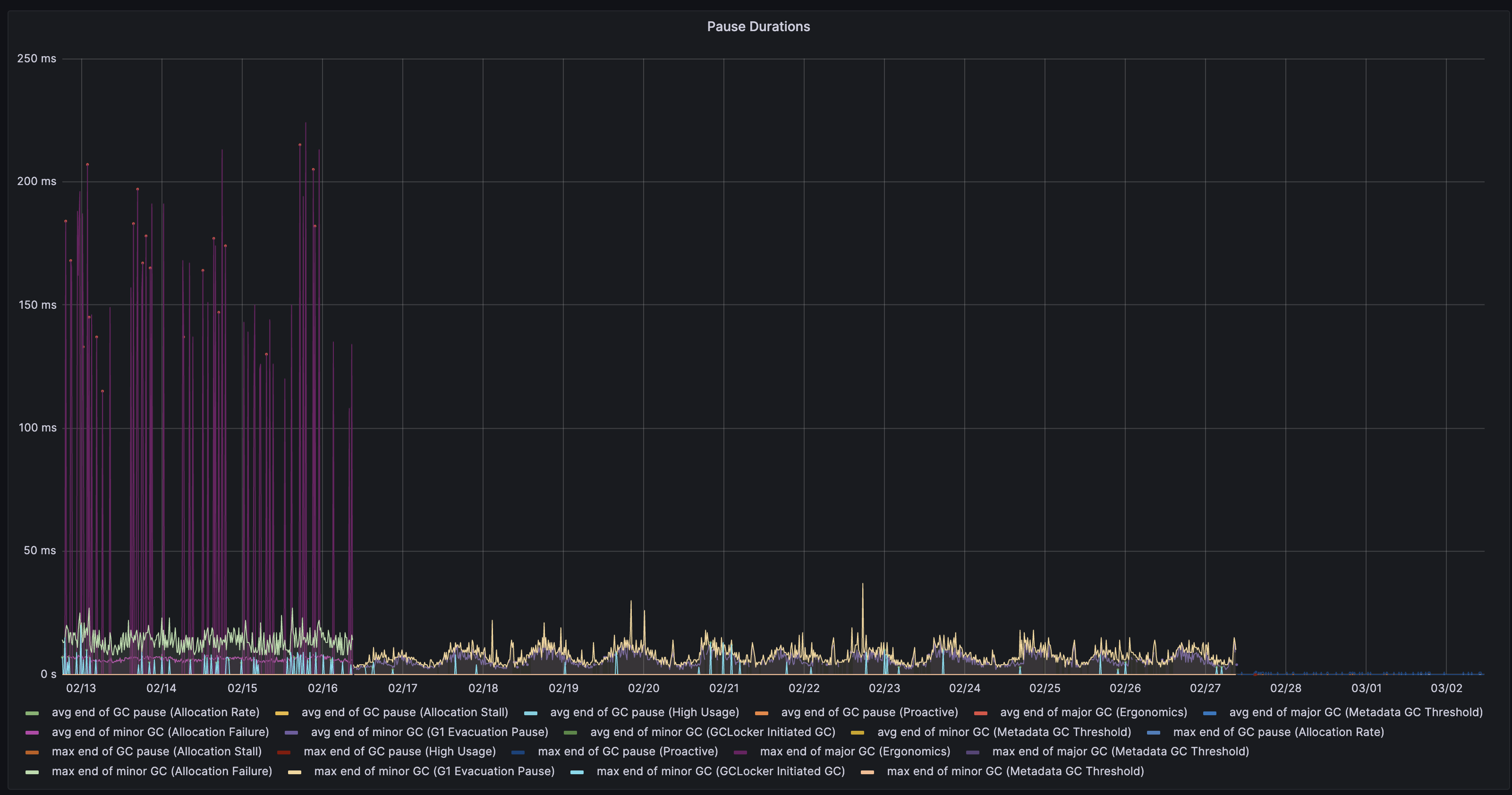
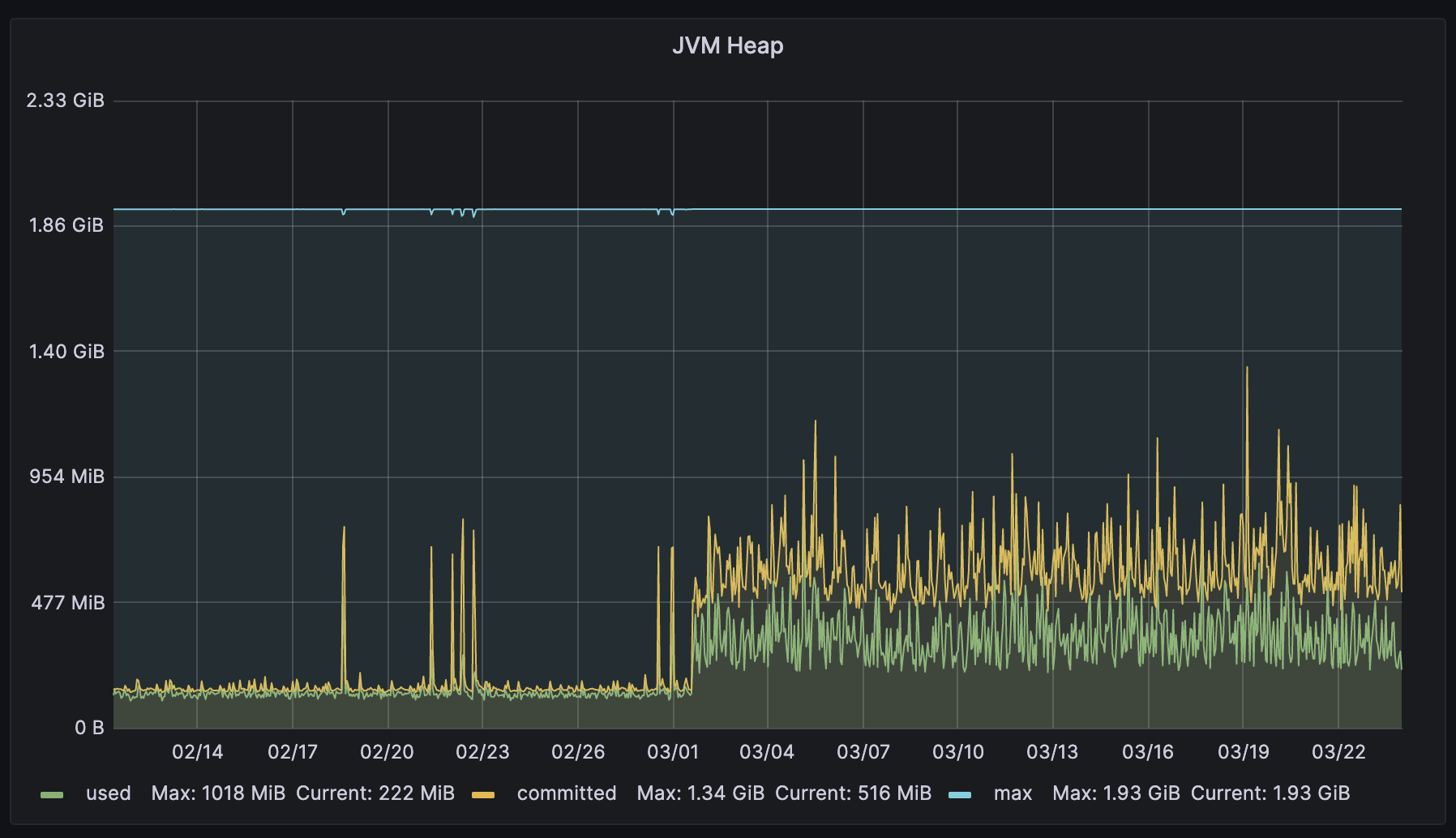
该应用的职责是收发消息,我们期望它以最快速度接收消息,以最快速度发送消息。每次GC会产生100ms左右的停顿,这个停顿在使用Java 17后下降到10ms,运行一段时间后,我们打开Java 17中的ZGC,停顿再次从10ms下降到0.1ms。假设每秒流入流出一百万条消息,100ms的停顿会影响十万条条消息通信,停顿下降至0.1ms时,仅有一百条消息受影响,用户可以更快速的交换消息。
当然这是有代价的:用了更多的内存,用量是之前的2倍左右。
削减消息
我们还尽可能削减消息的流转,如下场景:
┌─────────┐ ┌────────┐
─▶│ Broker1 │◀──▶│ App1 │◀─┐
└─────────┘ └────────┘ │ ┌─────────┐
├─▶│ Kafka │
┌─────────┐ ┌────────┐ │ └─────────┘
─▶│ Broker2 │◀──▶│ App2 │◀─┘
└─────────┘ └────────┘
中间件(Broker)与应用(App)组成一个集群,上述为两个集群,当Broker1的消息流入App1后:
- 假如 接收者在集群1上,App1将消息回发给Broker1转发出去
- 假如 接收者在其他集群上,App1将消息发送至Kafka,其他集群App会收到这条消息,其他集群App会判定:
- 假如 接受者在本集群上,App将消息发给本集群Broker转发出去
- 假如 接收者不在本集群上,消息丢弃
流程存在额外消耗:
- 从App1发送给Kafka的消息,会再次从Kafka流回App1,消息不属于App1所在集群,必定会被丢弃
- 消息还会被拾取多次,发往集群2的消息,集群2之外的所有App都会拾取、处理、判定后丢弃,即:一条消息的流出流量会被放大到与集群数量同等数量的倍数。假设线上有10个集群,1条消息就会产生10倍流量,其中90%流量是浪费的,且App也要浪费CPU时间来处理消息
优化很简单,消息收发时指定Kafka Topic,有明确的入和出,可根据不同的业务场景,判断消息是否需要进入Kafka中。
优化效果很好,上游和下游的应用负担大幅减轻,因为消息流量会至少被削为1/N,即:如果有2个集群,至少能削减50%消息流量,如果有3个集群,至少能削减66%消息流量。以此类推,集群越多,效果越明显。
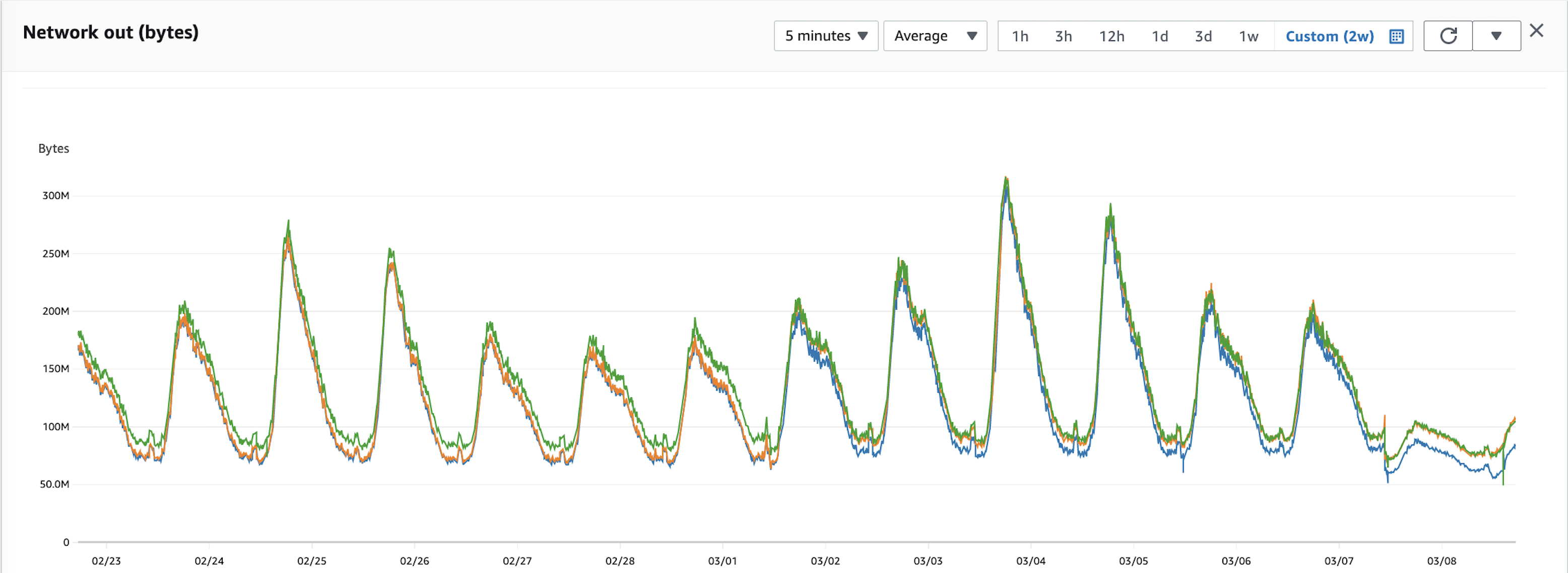
优化结果
让用户更快速进行消息交换的同时,大幅降低运行成本。
跨区流量费用当月至少下降50%。当然图片里不止50%。实例费用是我们目前支出最大的费用,应用所在实例CPU占用率都是对半砍,意味着我们可以直接将规格降一档,费用下降50%。
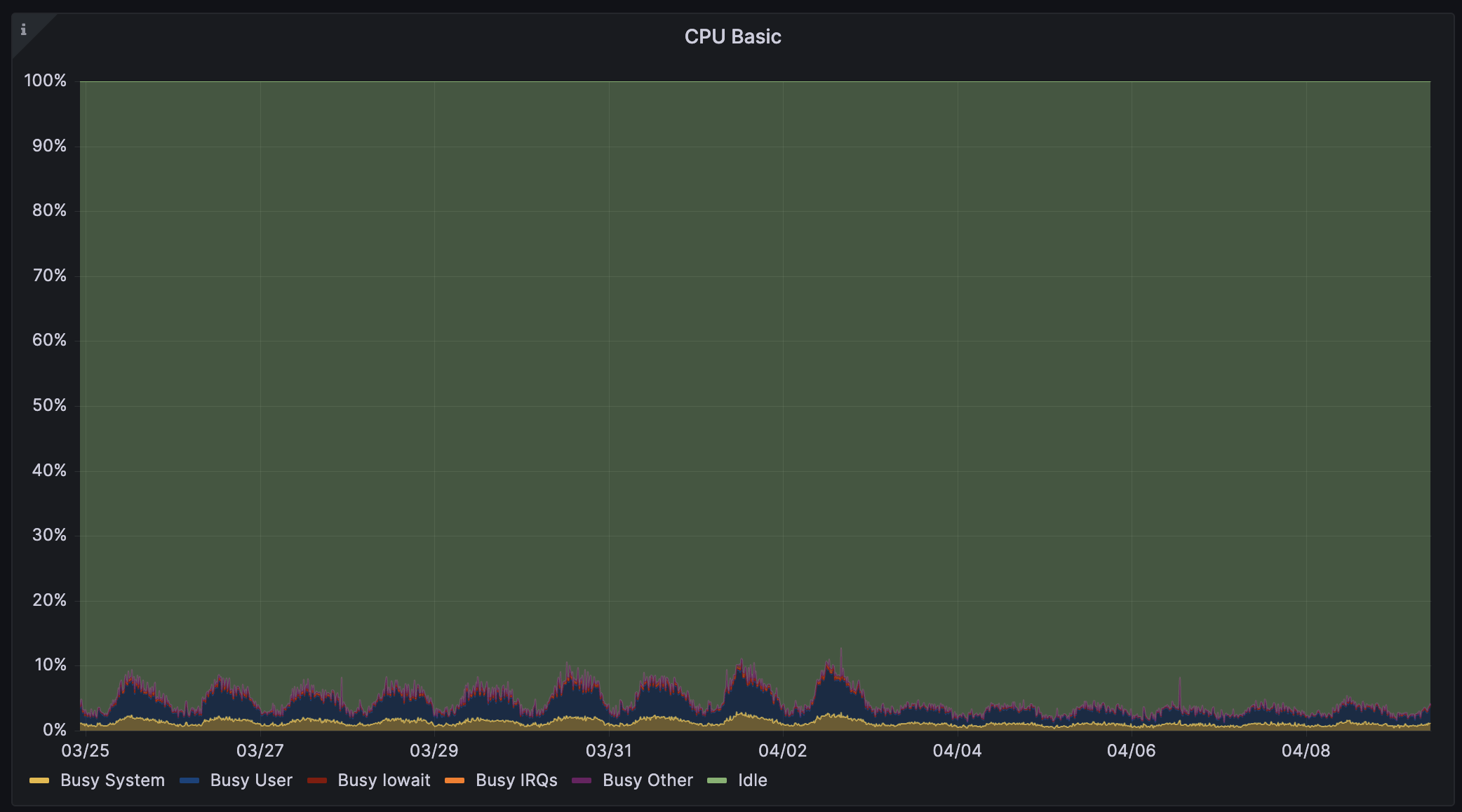
而我们在中间件上做的优化比这个还要出色。
中间件上的优化
我们进行了各类中间件版本的升级,更方便地进行配置变更和排查问题。调整了一些虚拟机和系统内核的参数,以便让所有中间件在最合适的状态运行。故障时不需要人员介入就可自行恢复。
迁移SSL/TLS连接不再是问题
要做的并不仅仅是升级集群里的中间件,还要迁移集群上的用户。中间件不支持热更新,业务很难做新旧集群兼容,迁移时只能将旧Broker上所有客户端连接断掉,再重连到新Broker上。进行迁移时,我们还得尽可能减小影响面,让更少的用户感知到通信中断。十分困难。假设一个集群上有10万连接要迁移,断掉的瞬间客户端会进行重连,10万连接会打入到新Broker上。新Broker要承受得住瞬时并发压力,且集群中立即广播10万的连接断开事件,还有接下来涌进来的总计10万的连接建立事件。
早些时间文章使用HAProxy支撑SSL/TLS高并发连接内描述过,阿里云中国区的CLB并不支持SSL终止,建立一个连接的成本很高,进行中国区迁移时,就出现打爆HAProxy的情况,始终无法建立连接,导致服务一段时间内无法恢复,即使是深夜,也有很多用户察觉到了问题。当时真的束手无策:
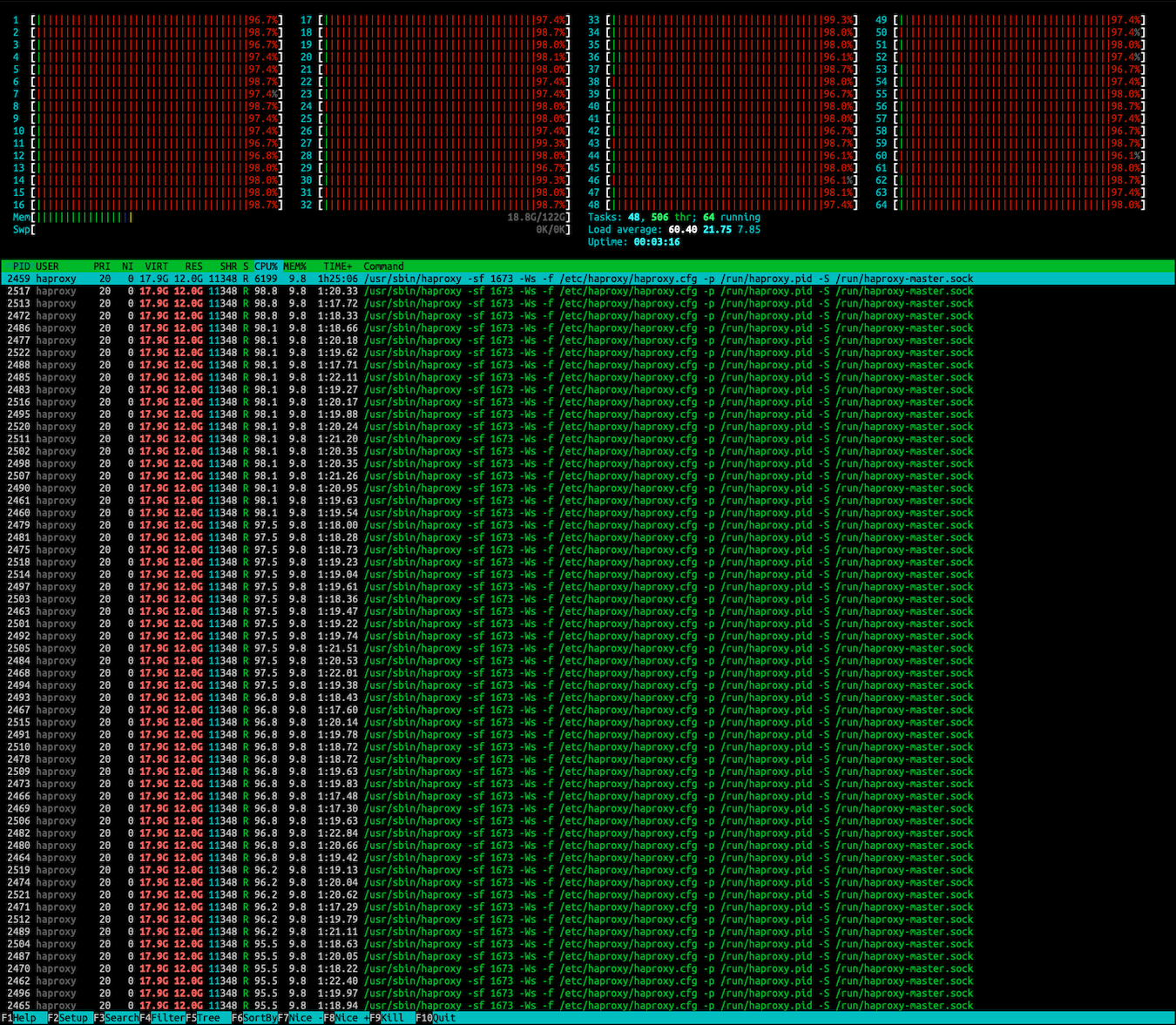
由于非中国区的机器不需要处理SSL/TLS连接,每秒建立数十万连接很轻松,这次迁移也让我们所有人都把这块知识补齐:
-
TCP在建立连接时要经过3次握手,服务器这边会将TCP的状态分为SYN_RCVD和ESTABLISHED,前者等待应用处理,后者已建立好连接。两个状态分别放在两个队列里,存放SYN_RCVD连接状态的队列叫SYN Queue,存放ESTABLISHED连接状态的队列叫Accept Queue。中文语境里,SYN Queue被称为半连接队列,Accept Queue被称为全连接队列。
-
这两个队列都有长度,我们认为我们实例性能很好,因此设置了一个很长的队伍。但HAProxy在一定时间内只能处理等待队列里的部分连接,排在队列中的连接未被处理,等待时间过长,被断开后进行重连,重新排入队伍。一段时间后,HAProxy处理队列中的连接时发现连接不存在,继续寻找下一个能处理的连接,客户端连接又在不断重连。最终集群进入完全不正常的状态:HAProxy占用所有CPU,一直在处理无法处理的连接,客户端连接不断重连却无法连接上,Broker完全没有CPU来处理正常连接的消息。
-
增加连接可以在SYN Queue的等待时间会大幅减小我们被大规模连接攻击时的存活几率。我们只能减小SYN Queue的队伍长度,这是正确的做法:HAProxy处理队列中的连接时能保证每个连接是能正常建立,速度慢了点但不会被大规模连接冲垮;SYN Queue满时,无法入队的连接会继续尝试重连,最终必定可以建立;Broker也有空闲CPU来处理消息。
至此,我们再也不用担心故障时中国区大规模连接无法进行重连。
大幅增加性能与稳定性
集群使用旧版本中间件时,其中一个中间件出现故障,必定会让整个集群无法正常工作,而新版本中间件则能够在极端的情况(如集群颠簸、负载均衡频繁闪断、大规模连接冲击)时都不会出现故障,即使出现故障也会自行恢复。这是我们升级的最主要的目的。
这让我们在进行其他区的升级迁移时,1分钟内超过百万的新建连接都可以完全撑下来。
此外,新版本中间件性能还有大幅提升:同样连接数的集群平均CPU占用率下降了一半,等效实例规格向上提了一档。如下图3台实例组成的集群,即使其中2台实例宕机,1台实例也可以轻松支撑集群承载的连接,而集群最大承载连接数增加至原先的3倍。
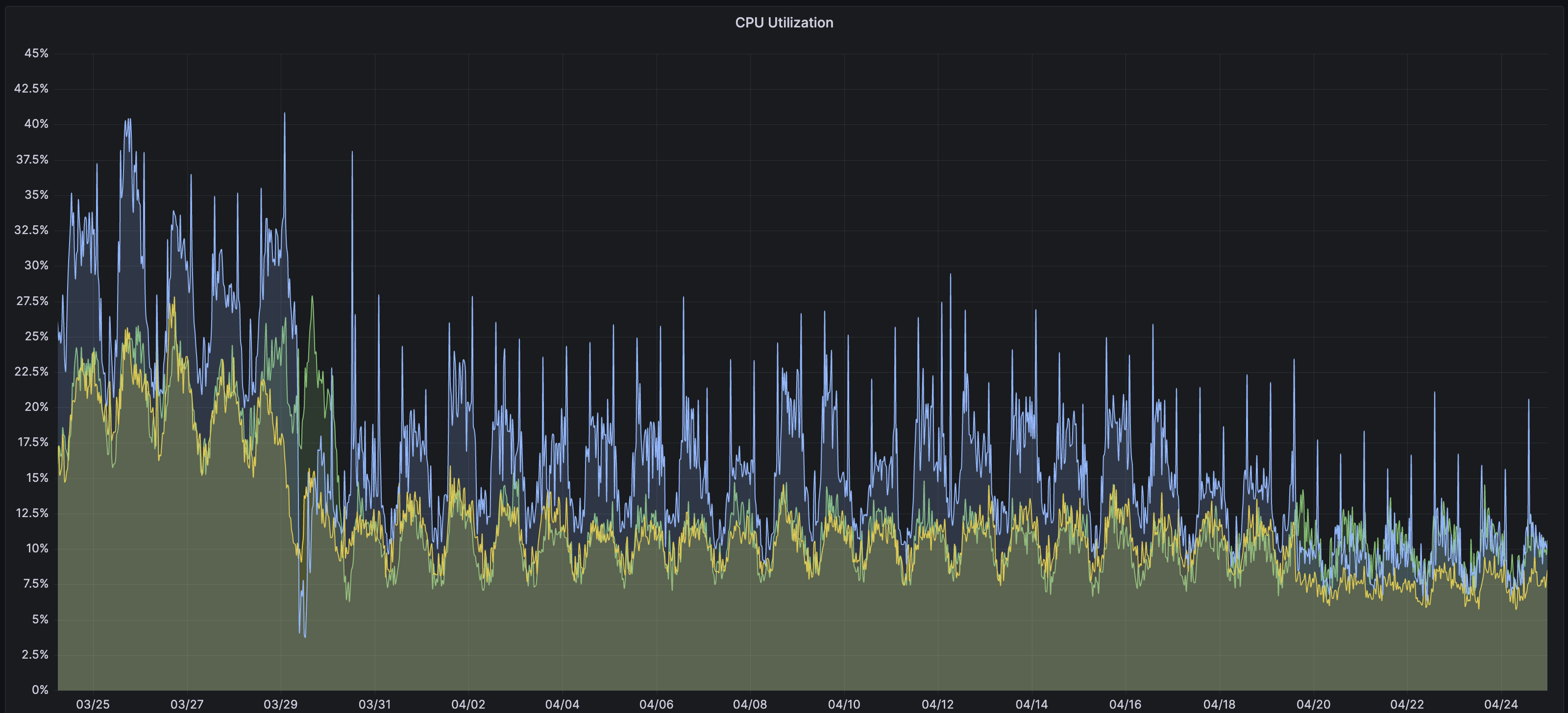
既然单一机器在集群故障时能够承载所有连接,运维就无需在集群故障时紧急恢复。我们缩减Connection Draining时间至120秒,实例出问题,120秒后负载均衡必定能将连接迁移至其他正常实例上。
后记
单纯承接千万级别的并发,实际上就是堆实例就行也不一定。但增加实例需要增加维护人力,故障率相同的情况下,更多实例会让故障实例数增加。我们的做法则是通过降低集群负载、提升集群稳定性,尽可能减少堆砌实例的数量。
升级应用组件,能让消息更快的在集群中流动;指定消息流向,能削减大量无效的消息流动,能降低整体集群的负载,单一集群震荡也再不会影响其他集群。
升级中间件,在同规格实例上有更好的抗冲击、自行恢复能力,还能承接更多的业务量,无须频繁扩容来支撑新流量。
大部分费用已全额预付且在架构调整前均为最佳状态,优化削减的费用会在下次预付预留实例才会体现出来。而新建的ARM集群费用对半砍,并已经服务数十万用户。我们在费用上的优化也得到了AWS技术团队的认可:皆是完美的100%。今天领导说我抠门程度在公司已经远近闻名。

感谢
此次架构变更,得到了公司很多团队的支持,中国区迁移出现故障时并没有责怪我们,而是等待我们解决问题,同时安抚上来投诉的客户。有了中国区迁移的经验之后,其他区的迁移平均每个集群不到5秒,没有他们的支持就没有后续顺利的架构变更。
我们是一个很小很小的团队,运维也只有不到1/4个人就是我,尽可能减少运维人力,缩短故障时间,给我们实际上是我减少更多的生产环境故障的担忧,同时给用户带来更稳定的体验。