
记一次线上数据库故障
我们在2021年10月15日遇到了一次线上问题,在全球一些地区出现服务不稳定的情况,3个小时之后,问题解决。以下时间均以中国时间描述。
发生了什么
我们生产上有张大表,简称TUAIM,这张表是我们系统数据增长最快的一张表,数据量也是最大的。在10月15日上午,这张表的索引比数据还要大。
从11时25分开始,有同事在生产数据库上对这张表执行了相当多的SQL,其中有一条导致数据库产生大量DataFileRead的SQL被执行:
select * FROM TUAIM WHERE TRIGGER = 'N' AND CREATE_TIME < NOW() - interval '90 days' order by id desc limit 1
这个SQL非常强力:
- 时间范围触发了接近全表扫描的消耗
- ORDER BY 进一步增加了资源的消耗
- 该SQL执行了近18392秒,约306分钟,约5小时
- 在SQL执行接近30分钟时,数据库的Burst Balance被完全耗尽
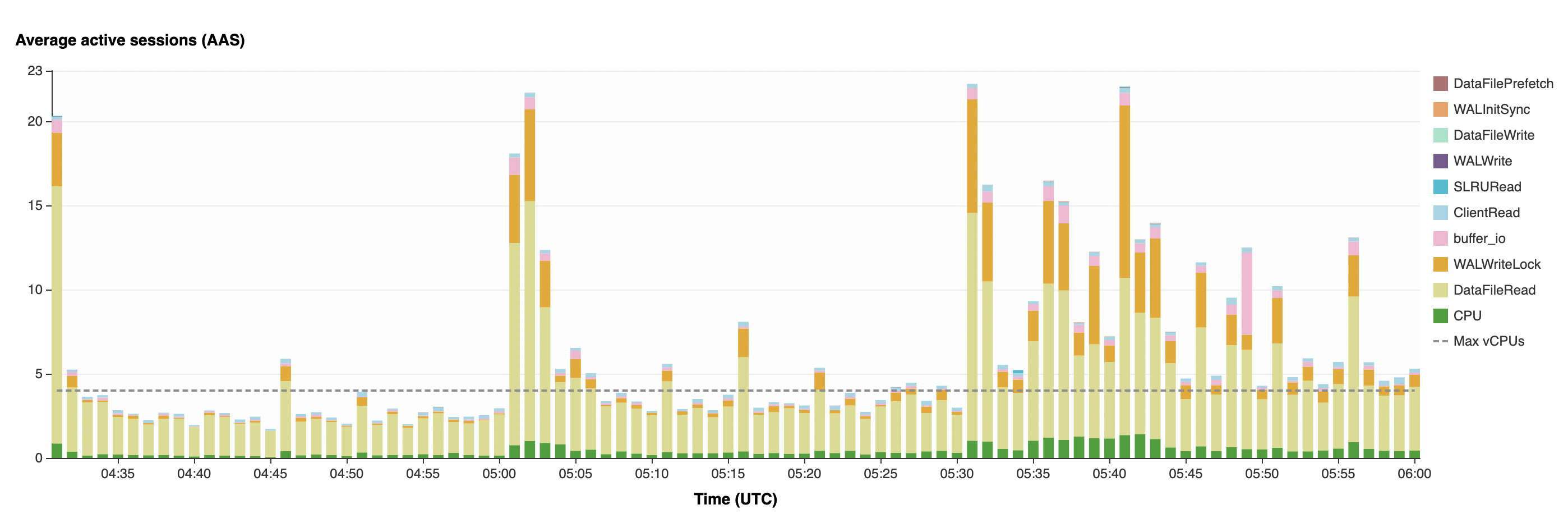
- 此时AAS开始飙升到20+,大量INSERT、UPDATE语句出现了WALWriteLock、buffer_io等磁盘响应的等待,也开始出现了近20ms的SELECT延迟
而在14时15分时,又有一条SQL被执行:
select TRIGGER from TUAIM where id > 97218974 group by TRIGGER
LIMIT 1000
这条SQL同样触发超大规模的DataFileRead:
- 虽然使用了ID进行范围查询,但使用了GROUP BY
- 该SQL进一步拖慢数据库的运行,执行了近8450秒,约140分钟,约2.5小时
- 这段时间因数据库缓慢,积压在数据库中的AAS达到了80+
- 在SQL执行近5分钟时,使用数据库的应用开始出现异常
14时20分,我们开始接收到应用的错误:
- 因SQL执行过长导致应用数据库连接池中连接无法及时归还,应用等待超时,开始抛出大量无法获取数据库连接异常
- 应用线程拥堵,其他应用调用该应用接口时间过长,开始抛出大量超时异常
- 我们开始介入
我们做了什么
15时03分,我们检查到Burst Balance耗尽,Write IOPS和Read IOPS总量只有450,无论是Write多还是Read多,都会影响其他性能,此时:
- 因IOPS被限制,任何操作都会对数据库造成额外的IOPS消耗
- Postgres为MVVC数据库,INSERT、UPDATE、DELETE操作则会有更大的消耗
- 我们在RDS Performance Insights上看到表象为大量的INSERT、UPDATE操作拥堵,第一时间认为杀掉执行时间过长的事务会有所缓解
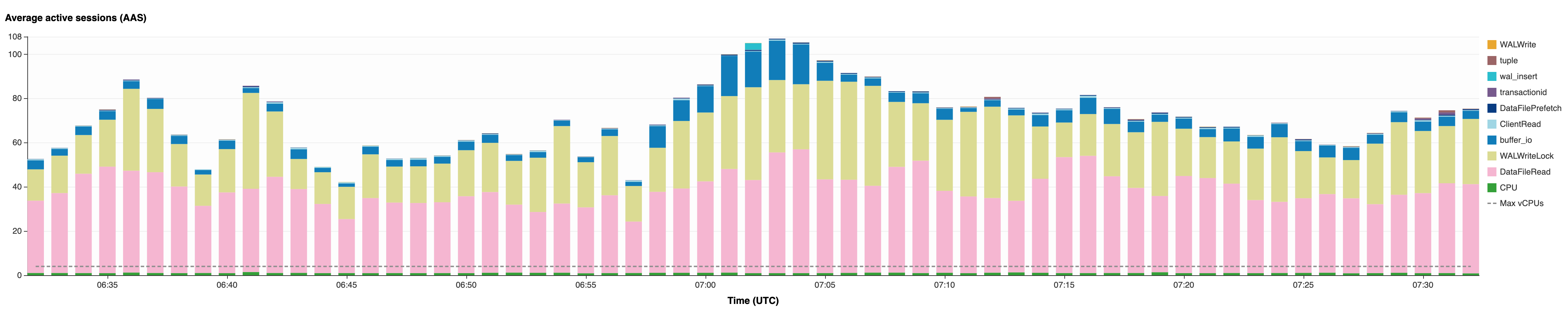
- 15时55分,我们将暂时与主业务无关的应用暂停;检查到有一个无条件更新的接口被频繁调用,我们将该接口黑洞掉,减少事务排入数据库,这些操作都有助于节省数据库IOPS
- 16时29分,我们还在等待数据库恢复,但大量用户已开始使用App并察觉到服务器异常,我们开始收到用户反馈
- 16时48分,我们决定将TUAIM表TRUNCATE掉,AAS从平均80+下降到60+,拥堵的SQL开始变少,延迟也开始下降,数据库开始恢复
- 17时28分,数据库AAS下降到Max CPU基准,延迟大幅下降
- 18时01分,被黑洞的接口恢复,同时通知客服问题已完全解决
- 18时06分,数据库Burst Balance恢复至1,表明数据库有余力承接目前的流量
更进一步
2021年10月16日0时26分,Burst Balance恢复至100,接下来的两天是周末,我们并没有对线上服务或数据库进行操作,这两天平稳度过了。
10月18日,我们开始进行改进和优化:
- 我们对无条件进行更新的接口进行了优化,在更新前判断是否需要更新,如果不需要就直接忽略,不向数据库提交事务
- 效果十分显著,原本一天百万次的接口调用,会触发百万次的更新,这个改动将更新减少了92%
- 数据库中的一些表由于频繁更新产生了索引膨胀,我们使用pg_repack将这些表的索引重建
- 表的整体大小都削减了20%,更新最频繁的表则削减了50%,索引空间占用减少了75%
- 一些Log表,原本的业务逻辑是 创建记录 -> 处理完成 -> 更新记录,我们修改为只创建记录,不进行记录更新了
- 更有可能的是不计入主数据库了,送入Kafka交给数据平台处理
在线上观察了一周之后,数据库的CPU和IOPS均有大幅降低的情况,工作日和非工作日忙时平均下降了10%,INSERT事务减少了50%,而UPDATE事务减少了90%:
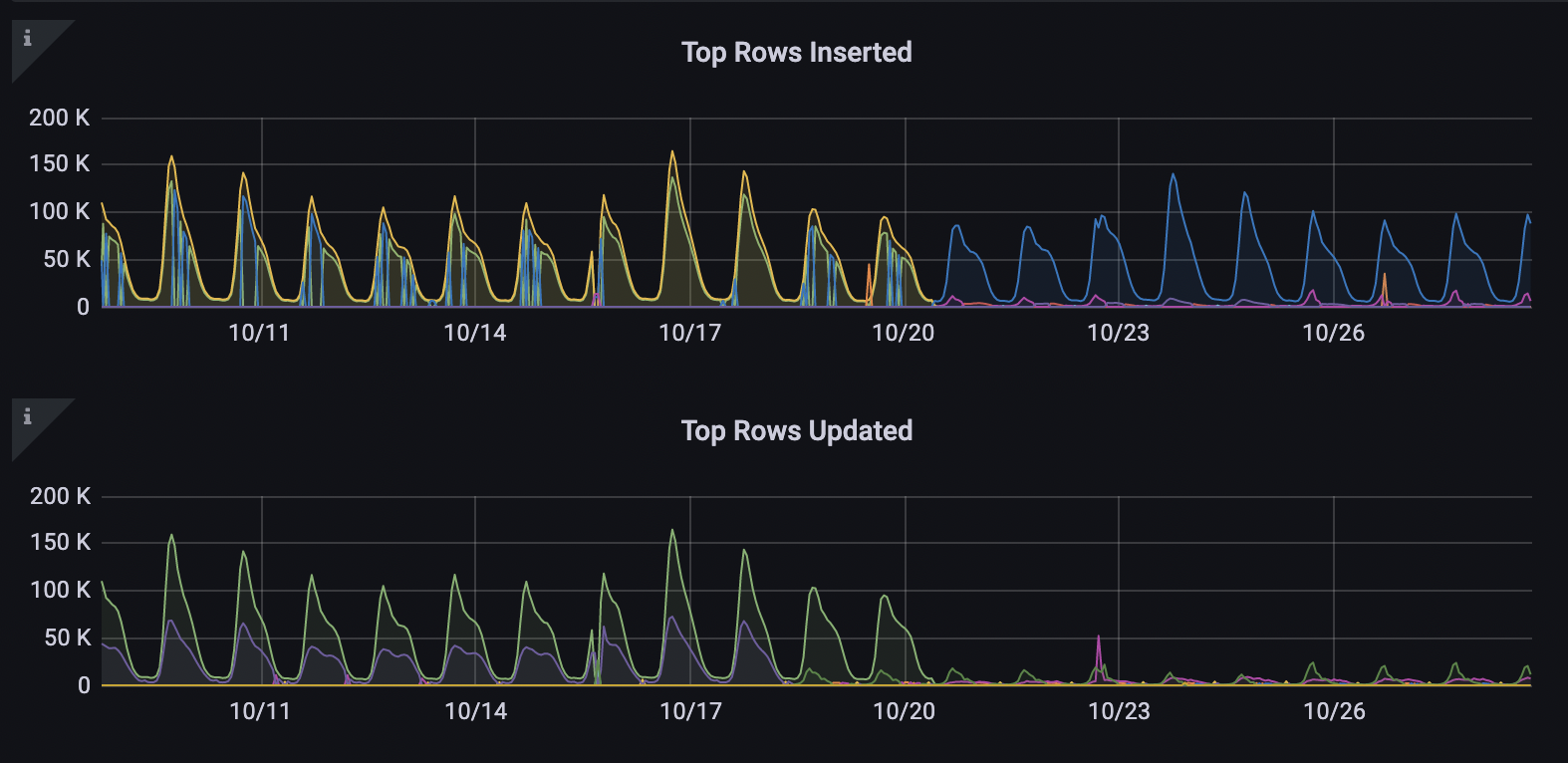
为了应付可能会到来的用户反馈,如询问他们的记录为何丢失,我们从备份中提取出了当天数据库的备份,并且做好了将这些数据导回数据库的准备。虽然有好几百封用户反馈信,但没有用户提出要恢复这些被删掉的数据。根据这样的情况,我们计划将这些数据在App端获取之后就从数据库中删除,这样可以保证数据库的性能不会再次被几个SQL打趴下。
同时为了避免这样的情况再次发生,我们新建了一个数据库只读实例(read replica),将我们非生产改动的查询限制在只读实例上,无论是长查询、报表都不会影响到主数据库的性能。
结语
我们已在团队内部进行了回顾和检讨,所以有了这篇文章。
我们对这次造成的所有用户不便表示抱歉。