
千万并发
2025年9月19日,我们负责的信息通信平台达到了全球千万并发,距上次写向千万并发前进的文章,相隔856天。
在这段时间内,我们在不间断实现各类业务需求的同时,还大幅改进了整体的运维架构,广泛使用了精心设计的多级缓存,达到了很高的系统可用性标准。实现上述目标的同时,还降低了22%的成本。
值得说的
并发数
上次有个朋友私底下问我“千万并发”是什么,这里的千万并发指:在某个时刻,有超过千万个客户端同时连接到我们的平台。
平台不仅需要维持千万个连接,还要对所有连接进行验证与鉴权,且要确保所有连接的通信安全。
连接重连
每个连接的建立都需要验证证书、交换密钥、密码认证与订阅信道,服务端都需要对该连接进行验证、鉴权、上线通知与信息登记。每个连接的断开会触发服务端的下线通知,清除会话与清理缓存。
因此,我们将连接重连视为很重的操作。客户端大规模重启,或是未经通知就变化的负载均衡器调整与实例宕机,都会产生大规模的连接重连。并发数越高,连接重连的规模也就越大。
连接重连对服务端造成的压力传导到中间件与应用,堆积的压力如果不能尽快消除或缓解,就会引起集群震荡,影响服务质量。当集群中的任一中间件如果无法承载压力,被击穿后引起集群雪崩,整个集群被冲垮,服务会完全不可用。
抗冲击架构
一开始,我们通过增加集群来暂时回避这个问题:负载小,故障时就不会撑不住;也让我们获得了喘息机会,能从完全未知的领域中争取时间来观察与学习。
所有连接的状态在集群中是共享的,任何一个连接接入集群,该连接的状态会传递至所有的实例,这让我们一开始就认为,集群中的实例越多,需要传递的消息数也就越多,所以我们没敢增加更多的实例。
之后我们发现,每个连接状态改变是以广播形式传递给下游,故障时会有数百万上下线消息产生,当下游应用消费缓慢,这些消息堆积在集群里,进程阻塞引起状态不一致,堆积消息过多引起内存快速上涨,都能引起集群异常。
我们优化了上下线的处理方式,用消息队列来接力消息洪峰,缓解了这个问题。
+----------+ +----------+
| | | |
+----------+ +----------+ +---->| Broker1 |------>| App1 |
| | | Load | | +----------+ +----------+
| Client |----->| Balancer|-----+ +----------+ +----------+
+----------+ +----------+ | | | | |
+---->| Broker2 |------>| App2 |
+----------+ +----------+
云服务商提供的负载均衡器会对注册在负载均衡器中的实例进行健康检查,当集群中的一台实例宕机,在该实例上的连接会转移至集群中的另一台实例上。
每家云服务商都有不同的“转移”方式:AWS CLB有个不知道应该是开还是关的Connection Draining开关,打开时,宽恕期后会强行故障实例上的所有连接,产生瞬时大规模连接重连,关闭时,只要实例有些许不健康(即便是云上内部网络问题引起)就会切断实例上的所有连接,产生瞬时大规模连接重连。阿里云CLB则是温和地将故障实例上的连接一批批卸下,再一批批连上。事实是:AWS CLB造成的瞬时重连规模比阿里云CLB的要大得多。
这和我两年前得到的结论稍微有点差异,正确的应该是:集群应根据瞬时负载、集群规模与配置,而不是根据连接特性,来调整连接速率。
再次把可以优化的地方和各类中间件配置全都过了一遍,我们认为我们可以往集群里添加更多实例。好处是整个集群能有更多机器来分散压力,有更好的抗冲击能力,坏处是集群间通信流量会上涨,且故障率更高。评估下来,好处比坏处要多,小范围试验效果十分不错,于是我们扩建了所有集群。从验证到全部应用,历时10个月。
但扩建不代表成本上涨,小集群在单台机器宕机时需要更多冗余,我们将原实例机型降档,实例数量翻倍,价格保持不变,需要预留的冗余更少,实例的利用率可以更高。
服务质量
除开并发外,我们的平台每秒需要:承接超5000次API调用、转发超10万条消息数。更快的API响应、消息转发能够给用户带来更好的体验,优化方向和动力都有了。
有个应用使用了Redis作为Token缓存,调用该应用API时,每个请求需要验证凭证,凭证则从Redis中查找。Redis查找很快,每个查找约1μs,但请求与结果之间的往返不快,约2ms。
主播主播,既然Redis有这样的问题,数据库有没有可能也会有这样的问题呢?有的兄弟,有的
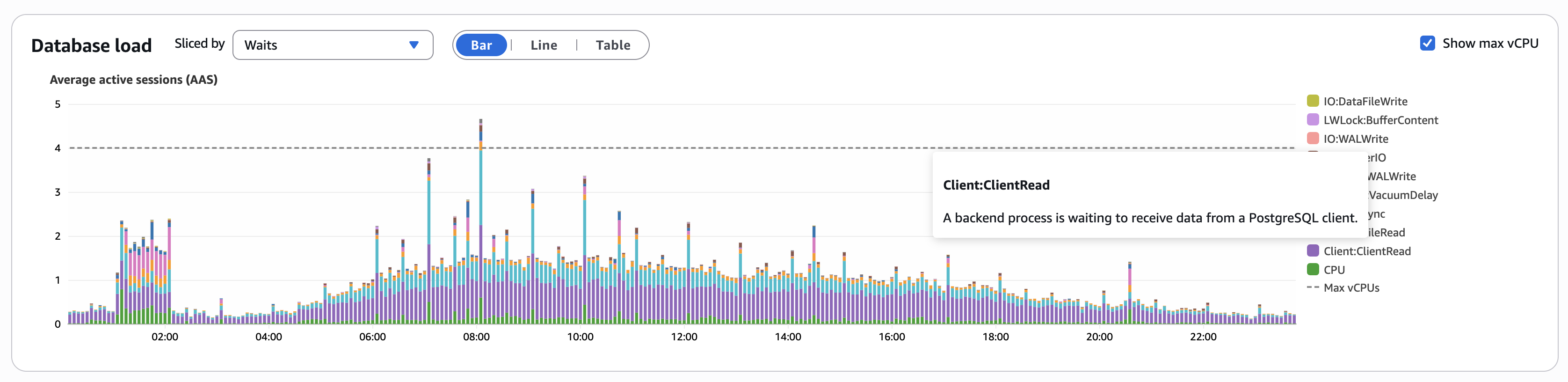
数据库活跃会话的监控图表中,有超过50%的Client:ClientRead,ClientRead会引起数据库会话阻塞,大量的ClientRead意味着我们有相当多数据在应用与数据库之间往返,业务量上涨,ClientRead的量也跟着上涨。
无论是缓存还是数据库,数据往返于应用与他们之间,变成了我们最慢的数据通路。目前能做的,就是尽可能的减少数据往返。
于是,我们重新设计应用里使用的所有缓存:频繁使用Redis的缓存迁移至JVM中,设置多级缓存;短时效的缓存设置为长时效;通过合理的缓存失效机制让上述缓存命中率提高;做好所有的缓存监控。最终,我们获得了这样的成就:
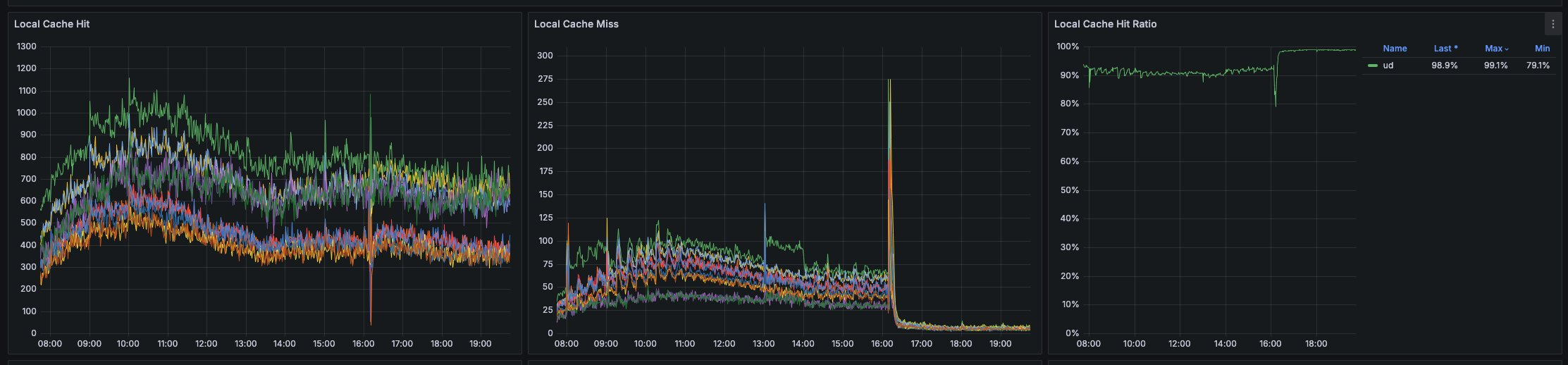
更进一步
我们实际上还可以进一步性能提升,但是总觉得稍微有点变态极端了。
我表明,这是目前能做的。Redis多路复用功能释出时,我们在上面收益非常大。当Postgres 18释出,新增的Async I/O特性则会大量削减ClientRead,从上面的数据库活跃会话的监控图表中,也可以看到我们仍然在使用4核处理器的Postgres数据库作为生产环境数据库。还有大量的性能提升手段都在等着这个特性,还可以更进一步。
说点别的
辅助角色
我是团队里的辅助角色。
我要保证团队里的所有成员能使用最新的开发套件、中间件。我要保证应用能有最优的编译速度、更小的应用体积、更快的启动速度。
我要保证平台SSL证书不会过期,数据库磁盘不会满,日志需要快速送到日志中心,所有应用运行都需要有性能指标。我需要定期去检查所有的应用运行指标,观察P95和P99,查找缓慢的地方。
系统设计
我没有设计千万并发系统的经验,我无法预测整个平台在更高数量级的流量下的表现。我通过记录每天业务量变化、中间件的运行状况、日志变化量这样的笨方法来了解整体系统运行的状况。这些指标积累了数年之后,我可以预测半年或一年之后的流量变化。当某个指标偏离正常范围时,我可以第一时间发现异常并及时行动。
系统设计初期,我需要为平台最初的快速上线做整体系统设计,选用的都是最简单和最流行的工具。平台正式上线了半年后,要考虑一年或多年后的扩展,能线性扩展的架构、带有指向转发的消息、高效的多级缓存,都是陆陆续续通过添加代码实现的。
该省省该花花
现雇主没有设置我花钱的上限,但我喜欢在有限的预算内实现合适的功能来解决实际的问题,而且还会不断去通过改进代码、使用新工具或中间件改进性能。这几年,每年我都在做减少成本的工作,效果都很不错,也摸到了很多中间件的性能边界。
同事用人力成本来教育我,说这样节省有点极端,从会议室出来我抱着镶钻的马桶哭昏在厕所,我只是不希望这些钱变成一些人贝〇斯或马〇私人游艇的一部分。我现在在用7年前的设备作为工作时的主力工具,我也确实可以去申请最新款的手机、最新款的高性能设备,实际上更希望省下来的钱直接转账到我银行卡里,说不定写完这篇文章我就跑去申请设备了。
至少现在还处于该省省该花花的阶段,只是有时省钱和花钱的方式奇奇怪怪引起同事的疑惑。比如会用多账号的方式降低特定区域的运营成本,比如购买翻新设备来节省15%的费用。
不可靠的同事
上面提到教育我的同事是一个领导,他是一个十分有能力的程序员,我的上级也是,他们两人保证了我们团队的基调:可靠。
大部分不可靠的人会在面试时被看穿后筛掉,小部分不可靠的人会在试用期时会十分尴尬地被筛掉,不管怎样,可靠是我们团队的一个基准。
今后
达成这个目标,原本这个事情可以找个借口搓一顿,当天组里有人说自己转正啦,有伙伴费啦,那就喝个果茶吧。手机传了一圈点好单,额外买了一杯送给领导。
我们前两周将集群扩容至1500万并发的容量,到达千万并发之后大家也都挺淡定的,除了催我让我写文之外。1500万并发应该不用写了