
阿里云Redis服务时延问题
前段时间我们在阿里云中国区上遇到了网络相关的瓶颈,解决这个问题花了一些时间,这里记录一下。
背景
我们的系统服务重度依赖Apache Kafka,它定义自身为事件流平台,我们把它当成消息队列中间件来解耦服务,又将其作为缓冲流量洪峰的弹性层,非常万能。
最初的架构中并没有将它纳入,后面只是作为个人兴趣爱好引入。随着业务增长,我们渐渐把重要业务交给Kafka解耦,Kafka不知不觉将整体系统架构转换为事件驱动架构,系统架构变得更清晰更简单。
目前Kafka是系统的核心,每天过十亿消息在上面流转,它在配置十分普通的实例上发挥出惊人的性能。数据中心故障,集群仅剩1台的情况下还能正常处理庞大的工作量。我们依此认定:Kafka自身很难出现问题,对Kafka进行详细监控,就能更好地侦测到消息流动时出现的性能问题。
我们完善了Kafka相关的监控和报警,方便观察业务峰值和增量。其中有个关键指标:Lag。将Kafka中等待消费的消息数定义为Lag(延迟),出现Lag表示服务无法及时处理送入的消息,需及时检查是否是代码导致的性能问题。如果是代码问题,改进代码,如果不是,说明当前流量已超过服务处理能力,需要扩容。监控系统每隔15秒对Kafka指标采样,如Lag在1分钟内仍超过1000,报警系统触发警告。
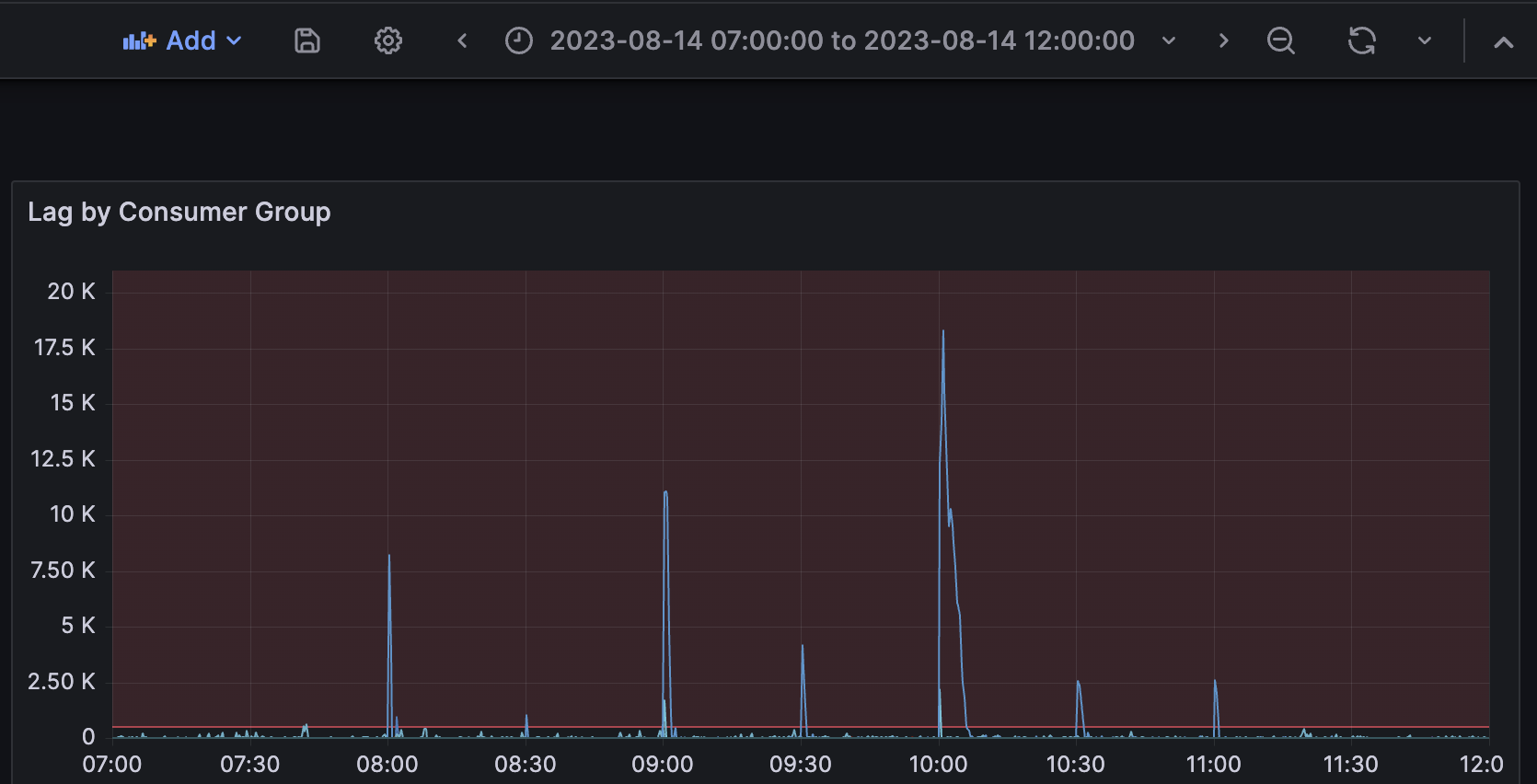
从上个月开始,监控系统侦测到Sawmill服务消费特定Kafka Topic时出现Lag,发出了多次警告,我们开始介入。
问题
我们检查了指标,出问题时的指标实际上不算夸张:
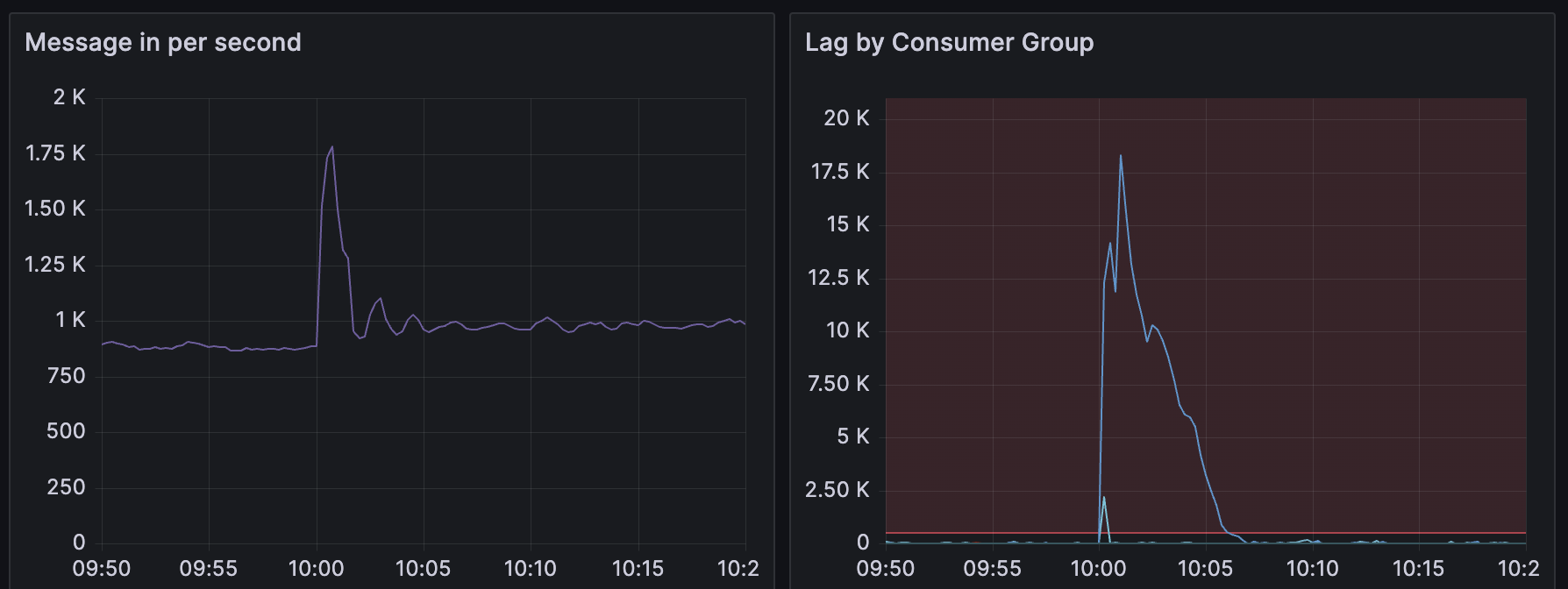
上述的指标有如下表象:
- 10点0分45秒的前15秒内消息平均收取速率为1.78K/s,同时间已侦测到大量Lag
- 10点1分0秒的前15秒内消息平均收取速率为1.5K/s,同时间Lag出现拐点,服务处理消息峰值能超过1.5K/s
- 10点2分0秒的前15秒内消息平均收取速率滑落至0.9K/s,Lag完全消除需要近5分钟。忽略速率波动,向上取消息平均收取速率1K/s,10点2分0秒时的Lag为10.7K,5分钟产生1K/s * 60 * 5 = 300K消息,服务处理速率为(10.7 + 300)K / (60 * 5) ≈ 1.036K/s
1.036K/s和1.5K/s差异有点大,回过头检查服务所在实例的CPU、内存、网络流量,都没有任何异常。此时我们认为,是服务消费速度慢了,新增一台实例可以解决这个问题。
然而新增实例后,问题没有解决,消费速度在反而更慢了。我们观察了一段时间没有任何改善,就又把新增的实例下掉了。
问题在哪?
没思路,画画示意图:
Msg ┌─────────┐ ┌─────────┐ ┌─────────┐
─────▶│ Kafka │──────▶│ Sawmill │──────▶│ Redis │
└─────────┘ └─────────┘ └─────────┘
- 消息流入Kafka
- Sawmill是我们的服务,服务从Kafka中批量取出消息进行处理:
- 需存储的数据会写入Redis,并设置过期时间,这是2次Redis交互
- 单条消息中包含数据量不等,有可能不需要与Redis交互,也有可能会和Redis交互数次,处理1批消息上限是1000条消息,平均需要与Redis交互约200-6000次
Redis是非常非常快的缓存,能在我们现在用的笔记本上轻松跑出1秒300万次操作的成绩,生产环境上的所有指标都十分健康,有可能是Redis的问题吗?
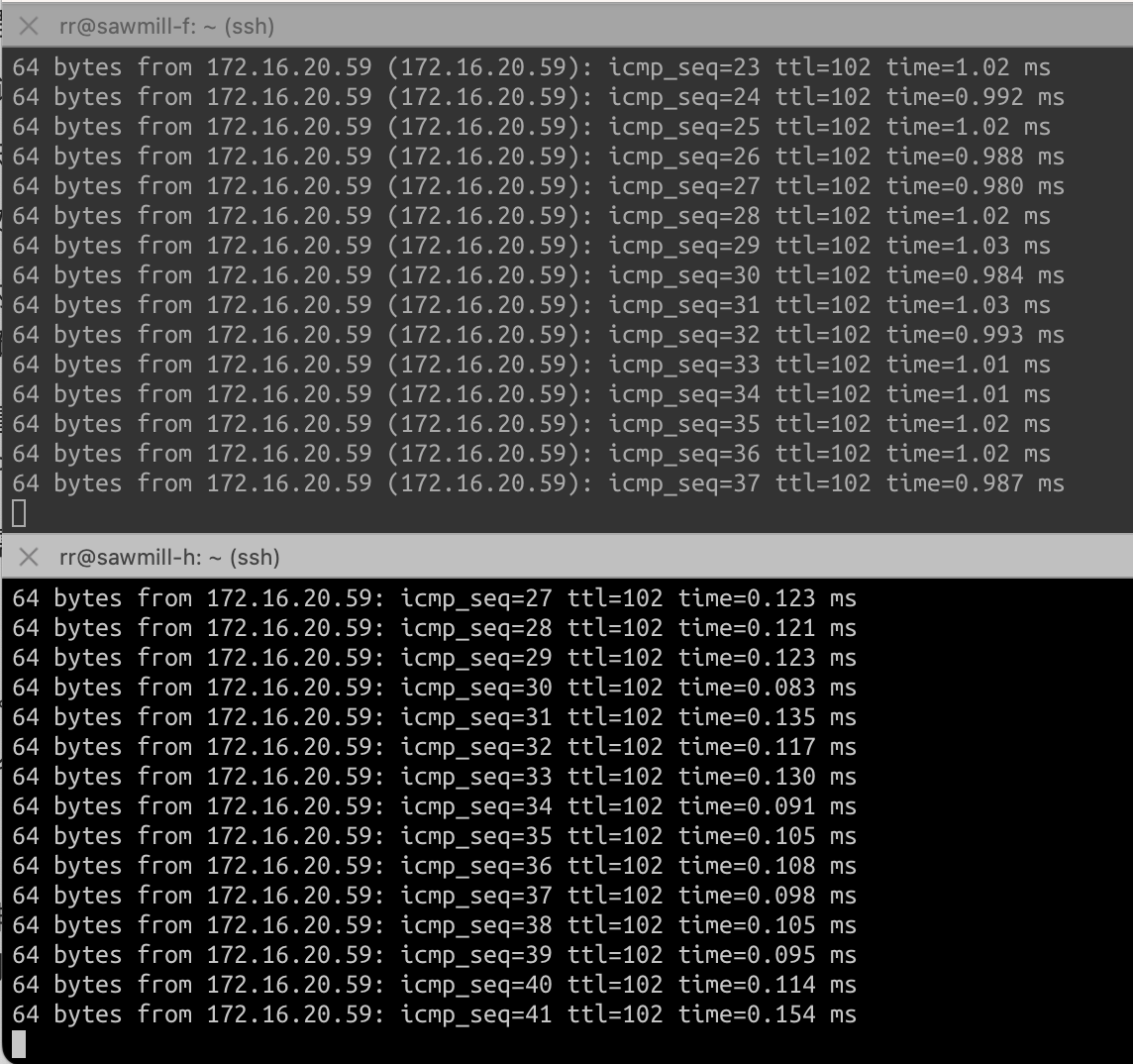
直到跳到两台Sawmill实例上去Ping Redis服务,确定是实例访问的链路慢了。
实例sawmill-f访问Redis的RTT(Round Trip Time,往返时间)是实例sawmill-h的10倍,这是一个相当夸张的性能差异。如每个Redis操作需要RTT为0.1ms,则表明1秒内可以进行Redis操作10K次,当RTT增加到1ms,1秒内能进行的Redis操作会下降到1K次。
性能差异根源是什么?
是可用区的问题,调用关系按照可用区来划分如下:
══════════════════════════════════════
AZ-F ┌─────────┐
│sawmill-f│─────────────┐
└─────────┘ │
══════════════════════════════▼═══════
AZ-H ┌─────────┐ ┌─────────┐
│sawmill-h│───────▶│ Redis │───┐
└─────────┘ └───Master┘ │
══════════════════════════════════════ │
AZ-I ┌─────────┐ │
│ Redis │◀──┘
└───Slave─┘
══════════════════════════════════════
sawmill-h实例与Redis Master节点在同一区域,sawmill-f实例则需要跨区访问,这是阿里云网络环境造成的差异。
把所有实例搬到和Redis同一可用区如何?
听上去为了更方便在篮子里面找鸡蛋,就把所有鸡蛋放到一个篮子里一样。可用区让我们的服务有更高的可用性和容错能力,我们不太能妥协仅使用同一可用区的架构,并且认为一开始选择了多可用区部署,就应接受这样的网络时延。
能接受这样的网络时延?
我们做过相当多的尝试,比如购买更高规格的实例,或类似网络增强型的特化实例来进行测试,RTT均在1ms以上,而能买到的实例,即便是1核0.5G内存的配置,只要与Redis节点在同一个可用区,RTT均在0.05-0.15ms之间。这应该是物理特性决定的结果,我们只能接受。
但并不意味着我们没有积极去思考其他方向:网络上的时延和带宽是两个概念,前者能衡量实例访问Redis的链路长短,后者能决定链路的负载大小。简单来说,时延是高速公路的往返时间,带宽是高速公路有多少条车道。一些QPS过千的服务跨可用区和Redis交互速度能超过2K/s,而Sawmill服务里消息均为顺序消费,或许应该回过头看看代码和配置如何改进。
增加多条车道?
我们从一开始就设计好了消息队列间Partition与消费者的对应关系,在并发上已经做好了优化:
┌Topic───────┐ ┌sawmill-f──┐
│ Partition0 ├───▶│ Listener0 │──┐
│ Partition1 ├───▶│ Listener1 │──┤
│ Partition2 ├───▶│ Listener2 │──┤ ┌─────────┐
│ │ └───────────┘ ├──▶│ Redis │
│ │ ┌sawmill-h──┐ │ └─────────┘
│ Partition3 ├───▶│ Listener0 │──┤
│ Partition4 ├───▶│ Listener1 │──┤
│ Partition5 ├───▶│ listener2 │──┘
└────────────┘ └───────────┘
目前Topic有6个Partition,每个Sawmill服务中设置3个并发监听,要让sawmill-f的消费速度和目前sawmill-h持平,需要将现有规模增至10倍,即将Paritition扩至60个,并将Sawmill服务并发监听调整至30。增加Partition有好有坏,在无法确定通过增加Partition数量达到预期效果的前提下,我们犹豫了很长时间,因为Partition只能增不能减,且变更数量后又要同步修改Key的算法,不影响其他数据中心就要针对中国区进行特殊处理。
既要又要,有点端着架子
是有点,我希望通过设置简单的架构和精巧的代码来抹平云平台间的差异,在这个问题上卡了近两周,稍微有点焦虑。
实际上只消除Lag的解法有很多,比如将消息搬迁到JVM实例内存中慢慢消费,比如将消息又再次转发到其他队列中,但这些做法无法让数据及时落入Redis,仅消除Lag,但增加了消息链路时间,我觉得是在掩耳盗铃。
阿里云在周日正午发邮件通知我们Redis周一凌晨1点维护,我重新设置好维护时间在凌晨5点,联系了中国区客服告知潜在运维变更可能会导致的问题。接着我还得和同事解释,我没有修改任何生产配置,故障不是我引起的,变更也不是我发起的。第二天凌晨5点睁开眼,检查了线上运行数据,一切都正常,但问题依然存在,还需要解决。
最后问题是怎么解决的
我们通过Spring Data Redis的文档搜索performance找到解决问题的关键,文档中的Pipelining章节中有如下这段话:
Redis provides support for pipelining, which involves sending multiple commands to the server without waiting for the replies and then reading the replies in a single step. Pipelining can improve performance when you need to send several commands in a row, such as adding many elements to the same List.
Spring Data Redis provides several RedisTemplate methods for running commands in a pipeline. If you do not care about the results of the pipelined operations, you can use the standard execute method, passing true for the pipeline argument.
突破口在RedisTemplate.execute()上:将不需要返回结果的所有的操作放置在一个pipeline中,RedisTemplate会自动帮你把所有的操作合并成一条操作送到Redis。看上去很简单,实际上要写很多代码。
redisTemplate.execute(conn -> {
operations.forEach(operation -> {
conn.hashCommands().hMSet(operation.getFirst(), operation.getSecond());
conn.keyCommands().expire(operation.getFirst(), Duration.ofHours(36).getSeconds());
});
return null; // do not care about the results
}, false, true); // expose connection -> false, pipeline -> true
即使操作有成千上万个,上述代码会将所有操作合并为一条指令发往Redis。
性能变化如何?
性能超幅上涨。
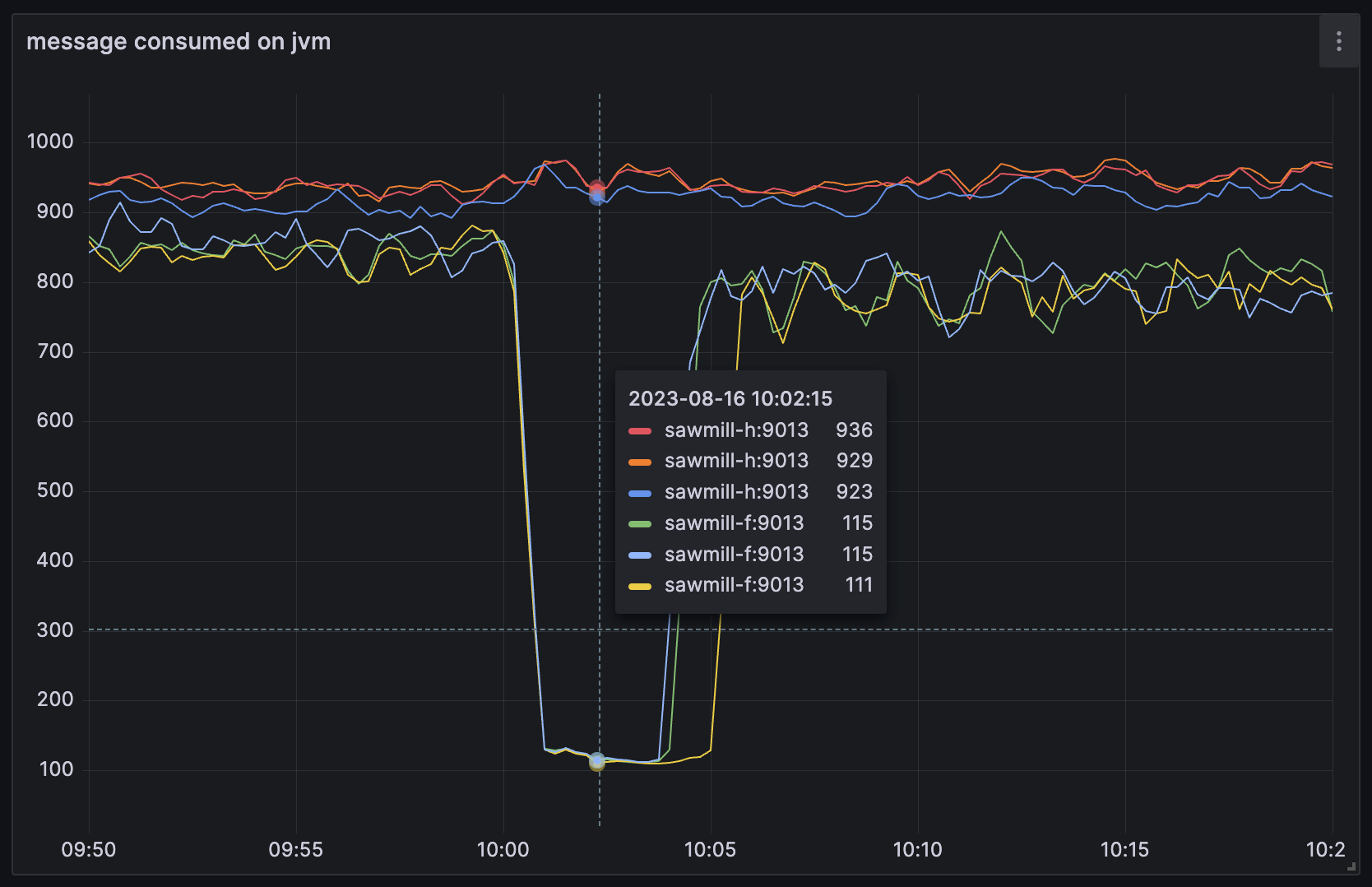
在开发环境验证后,接着在生产环境上架好了APM,对比不同可用区、代码改动前后的性能指标就可以看出来差异,接下来就是收集数据与填表:
| 每批最大消息数 | 闲时P99(ms) | 忙时P99(ms) | |
|---|---|---|---|
| sawmill-f 改动前 | 5000 | 463.88 | 86296.06 |
| sawmill-f 改动后 | 5000 | 19.41 | 22.29 |
| sawmill-f 改动后 | 10000 | 18.28 | 28.29 |
| sawmill-h 改动前 | 5000 | 66.24 | 1254.37 |
| sawmill-h 改动后 | 5000 | 9.27 | 18.66 |
假定sawmill-f访问Redis和sawmill-h一样快,不做任何改动,流量要涨到现流量的7倍时我们才可能有感知,且在很极端的情况下才会出现Lag,接着被监控系统捕捉到,最后通知到我们。
代码改动后,无论是忙时还是闲时,是否同一可用区,sawmill任一服务都能在30ms之内处理一批消息,也就是在1s之内能处理至少33批消息。我们很满意这样的结果,流量上涨到现流量的30倍会开始频繁出现Lag,而新增1台实例就又可以再支撑50%的流量,相当于现流量的45倍。
之前只要谈到阿里云你都会扯到AWS上,AWS数据中心没这个问题吗?
没有。AWS ElastiCache表现得非常好,即使流量数倍于中国区,我们没有遇到过访问服务延迟过高导致的性能问题。在易用性、扩展性和大量围绕Redis特性构建的设置上,AWS ElastiCache远超我们所有期望,且新版本跟进、补丁、新实例支持都非常迅速,并一直在提醒我们、鼓励我们使用更好的东西。
ElastiCache for Redis 7.0增加了多路复用技术,这特性可大幅增加吞吐,且大幅减少网络时延,我们只要进入AWS ElastiCache控制台,上面的小横幅就提示可升级到新版本上获得更好的性能,或提示我们可以考虑一下较新的实例,有更好性价比。提示我们升级Redis 7.0的提示被我按掉了

我的个人观点:根据我现在具有的知识,我可以写一篇上万字的文章细数AWS ElastiCache的优点、设计上有意思的地方,如何伸缩集群,如何轻松做Redis读写分离。我想到的和超过认知的东西都提供了,而且做得很好。我觉得,设计与提供AWS服务的人非常喜欢新东西,愿意站在和我一样的视角看问题,有新东西会与我分享,并且真诚的在帮助我。这样的体验很舒服。
而我们购买的阿里云Redis服务为经典版实例/社区版,到目前还无法支持Redis 6.0。
感觉你认为AWS远比阿里云要好
啊…阿里云这样能让我们及时发现性能问题,并刺激呃鼓励我们自己去尝试解决问题,也挺好的。之前只要一开工单支持人员就让我抓包,我已经是个成熟的运维了,该学会自己抓包然后自己分析问题了,有时候不需要抓包就能解决问题,比如这次解决的问题,已经没什么好怕的了。AWS实际上也经常出问题的,云服务的事情不能一概而论,我曾在极度愤怒的情况下…
那现在Redis上已经没有性能问题了吧?
有的,我们还有个服务每天凌晨会产生数十万的Lag,并且要数小时才消耗完毕。
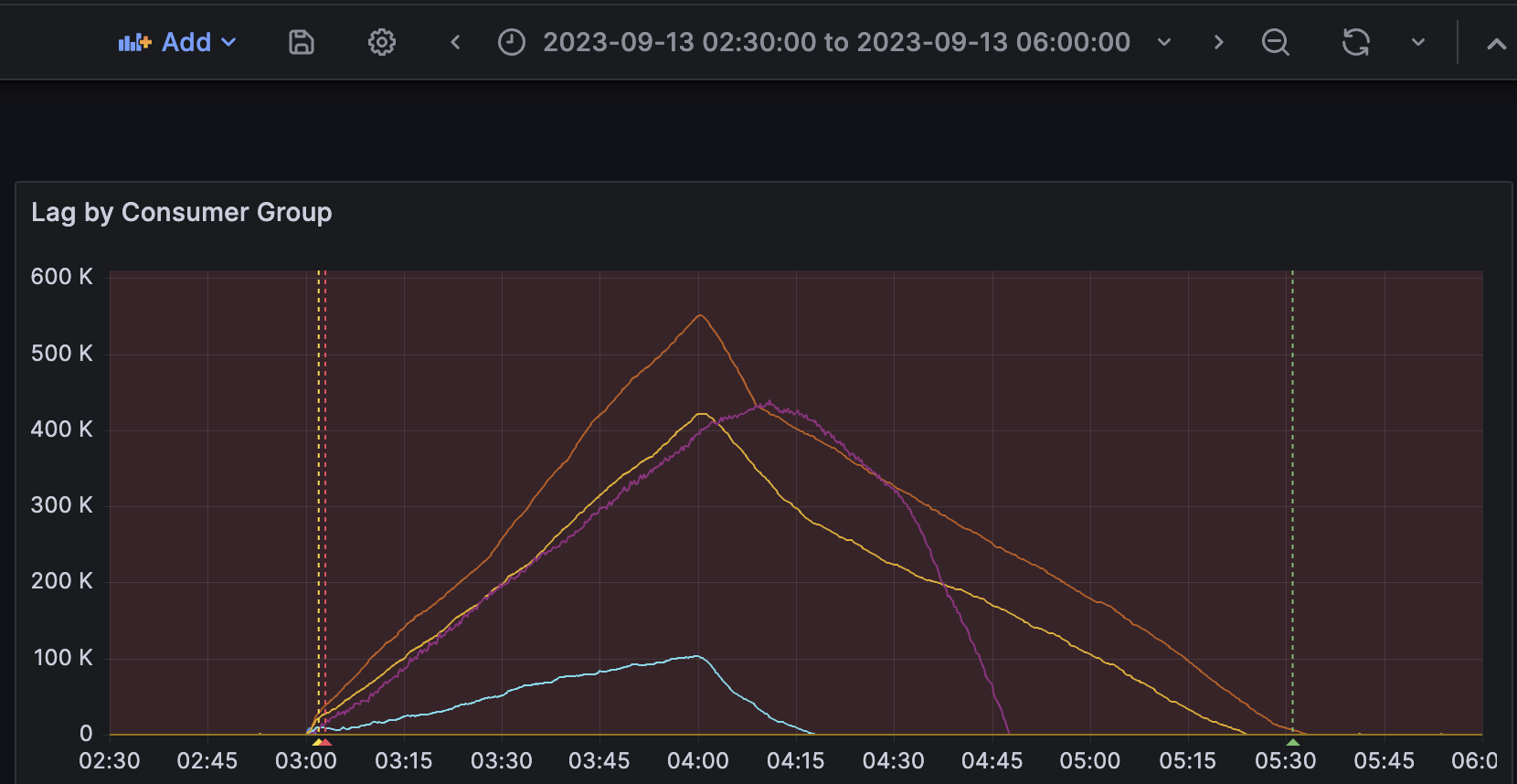
我们认为和Redis网络问题相关,已经着手进行优化,今天上线的版本砍了一半消息数,这能让凌晨Lag减少一半。
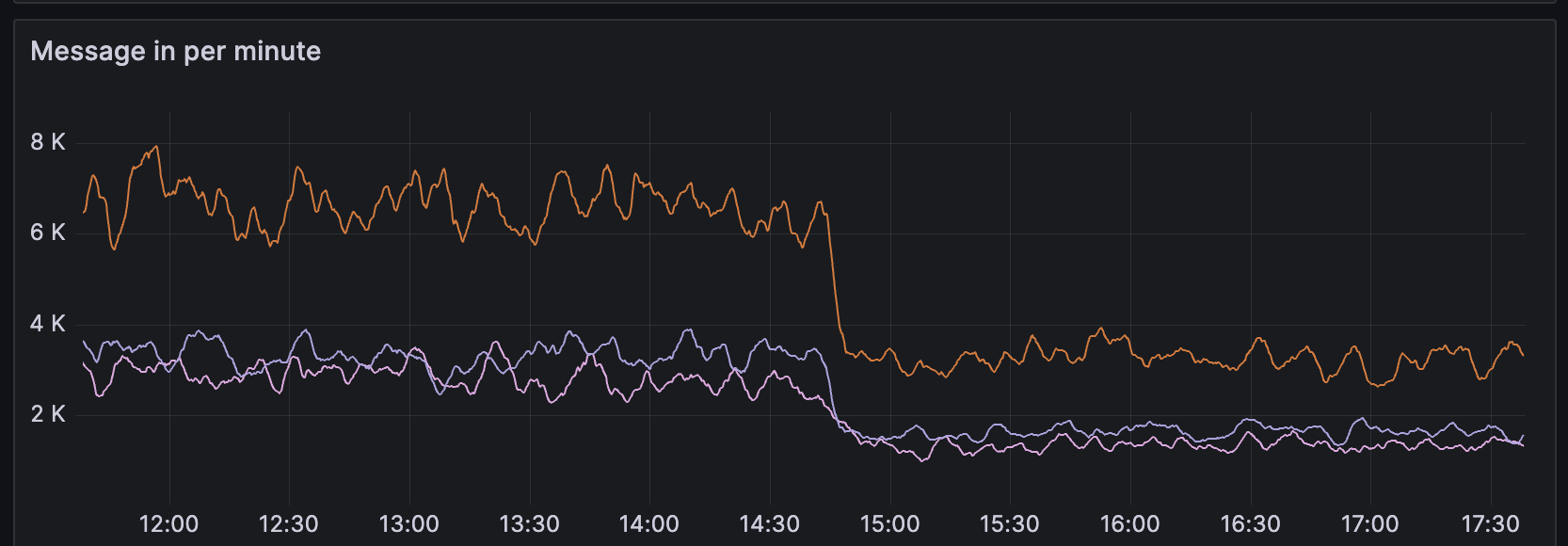
消除Lag的Pull Request已经提交,我们计划在下周发布,彻底解决这个问题。
🎉