
ClickHouse与超小型数据平台
ClickHouse是一个非常强大的OLAP数据库,初次接触时被它强劲的性能震撼到了,我将它投入到了正在建立的超小型数据平台中使用,以下是我这半年工作的记录。
开始筹划
超小型数据平台是产品经理在2020年年末的提议,用途是收集数据,将数据结果展示。因此我被产品经理抓了好几个月,让我在2021年过中国春节前把预算做好。当时估了个Hadoop平台的方案,每个数据中心需要安排10+台高配置实例,费用也相当高。
之所以叫超小型数据平台,是因为经过完整评估后觉得数据量不大,2021年年底一天数据量只有几千万左右。需求大部分是T+1报表,这个数据量上Hadoop平台有点大材小用,我需要寻找更简单的数据仓库、数据分析工具。
中国春节后回来发现了ClickHouse,在机器上一个Docker拉起来,照着文档找了几十亿数据塞进去,无论怎么COUNT、DISTINCT都是瞬间返回结果,全表几十亿数据求和不到1秒返回结果;复杂操作,如两表JOIN,还会有进度条给出预估结束时间和内存占用。我大受震撼,翻了很长时间的文档进行学习,仔细评估之后,我定制了如下的配置:
| 用途 | 配置 | 数量 |
|---|---|---|
| 应用 | 2C4G | 2 |
| Kafka | 4C8G | 3 |
| ClickHouse | 8C16G | 1 |
机器数量是之前计划的一半,配置不需要很高,预算砍了一半之后又再砍了一半。
ClickHouse的硬件要求写得很清楚:
ClickHouse implements parallel data processing and uses all the hardware resources available. When choosing a processor, take into account that ClickHouse works more efficiently at configurations with a large number of cores but a lower clock rate than at configurations with fewer cores and a higher clock rate. For example, 16 cores with 2600 MHz is preferable to 8 cores with 3600 MHz.
更多的核心比更高的主频有用,而内存的要求十分迷你,最低4GB内存,如果需要GROUP BY、DISTINCT、JOIN的话就需要更多内存,虽然这些场景都没有,但为了保险起见,我申请了8C16G的配置,避免频繁升级配置。
架构设计
配置和预算都提交申请之后,我开始设计数据结构和数据流。
数据格式
数据上传走的HTTPS接口,数据使用Protobuf V3封装,接口上用Content-Type限制住,还加了RateLimit、时间有效性检查,在无数据加密防护下能够提供较高的接口安全,在服务器端也有较少的CPU消耗。
为了让Protobuf更好压缩数据、减少流量消耗,定制数据格式的时候我将公共字段抽取出来,同类型的数据放在同一个List里,较大体积的数据压缩之后再放入List中,经过验证之后,与同数据量的RAW JSON相比,Protobuf帮助压缩这些数据到只有20-50%大小。
数据流入接口
接口使用了Webflux + Netty接受数据,用1000 Client对应用进行压测,在t3a.micro(2C1G)的实例上跑出了6000QPS的成绩,如果需要更高的QPS,升级配置或者增加机器。
接口收入数据之后,这些数据会按照类型分拆,打上标记,放入特定Kafka Topic中。
这个应用被命名为chainsaw。
数据处理
上游将数据放入Kafka之后,下游在接收到数据之后开始进行处理。
流程有点简单,同样是把数据取出,打上一些标记,然后送入ClickHouse。
这个应用被命名为lumberjack。
报表生成
通过触发定时任务,将必要的数据抽取后送入ClickHouse。再次通过触发定时任务,生成报表。
这个应用被命名为job。
架构图
综上,该架构设计为:
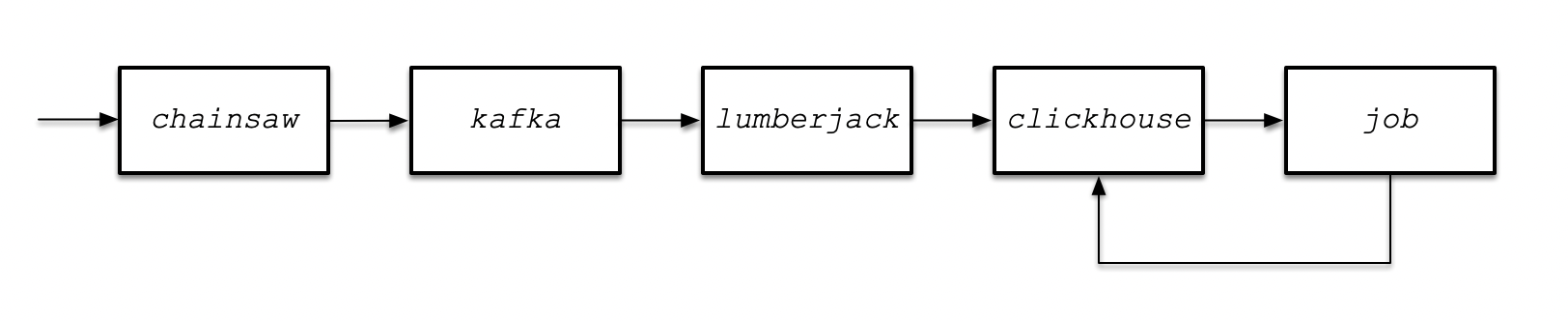
数据经过每一个节点都会被打上一些标签,其中带有经过每个节点的时间,通过这些时间标签,我可以算出数据经过多长时间上传到服务器,经过多长时间处理放入Kafka,在Kafka停留了多长时间开始被处理,又在什么时候落入数据库,从而我可以监测出来数据流动在哪个节点上出现缓慢。
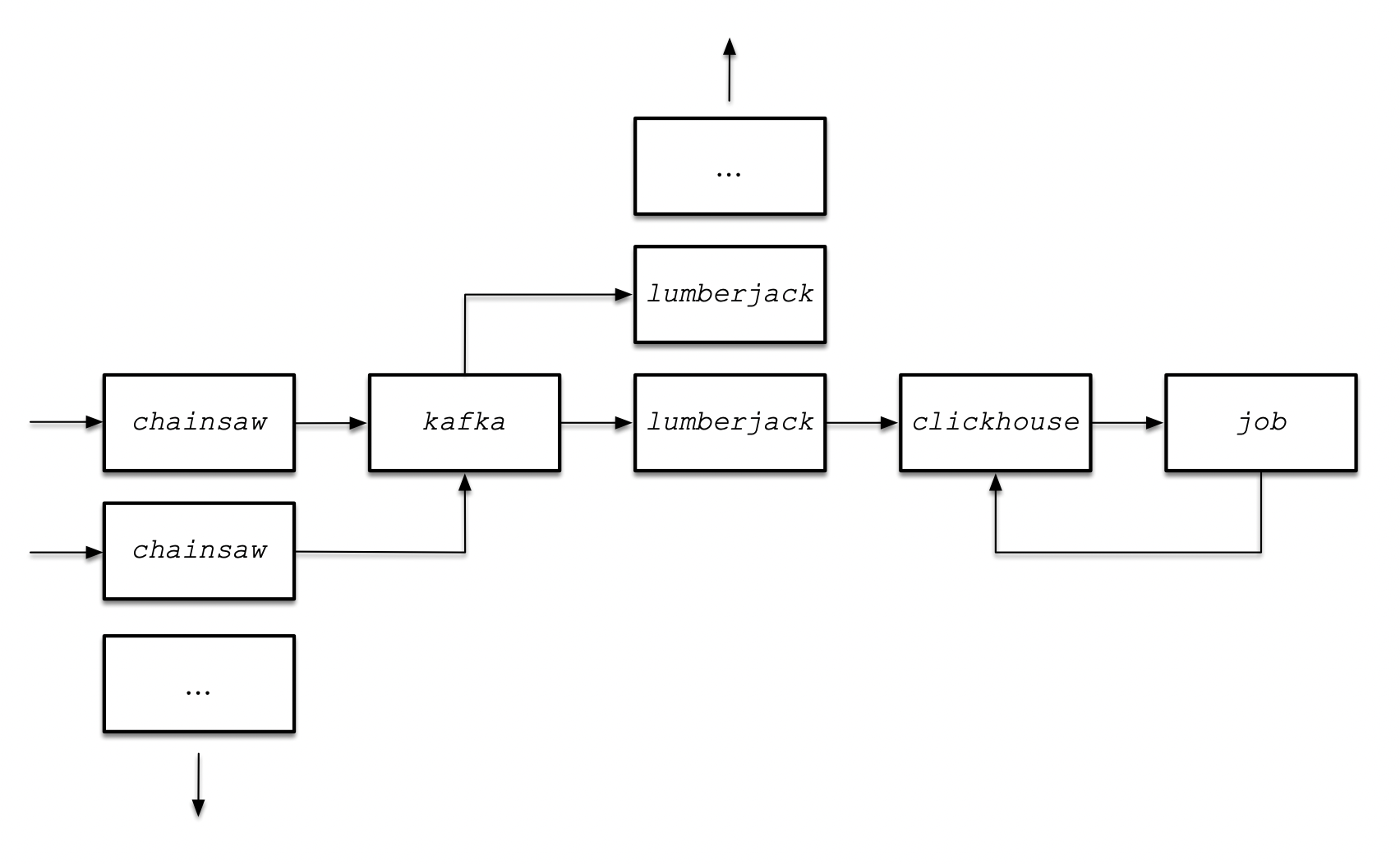
当数据流动出现缓慢时,每个节点可以横向进行扩展缓解:
- 流量变大出现缓慢,扩chainsaw
- 消息处理缓慢,扩lumberjack
- 落库缓慢,ClickHouse升配或扩为集群
- Kafka不会慢,每秒百万条消息时再考虑
- 数据量变多时Job会慢,但它有6个小时的宽限期来慢慢处理
此时架构变为:
这次设计和成型都十分快,初期的架构设计、代码、部署和投入使用在很短的时间内完成了。
数据仓库
和上述的架构相比,ClickHouse的使用更为重要。
翻ClickHouse文档的时候觉得里面的很多定义和规范很有意思:
- SQL方言稍微接近MySQL,表名和列名都是大小写敏感,使用多年Postgres的我需要适应
- 十分重视表DDL,需要指定ORDER BY,隐式指定PRIMARY KEY,可选PARTITION BY指定分区键
- PARTITION BY还可以指定以函数为键,严格的同时又有稍微放宽的地方,很有趣
- 指定列为空时,需要使用Nullable配合类型指定
- 文档高亮提示你:只要用Nullable就会引起性能下降
- 没有Boolean类型:
- 文档放了一个Boolean目录,点进去告诉你:没有Boolean,去用UInt8,把值限制为0和1就好
- INSERT语句和标准SQL无差异,但:
- 同时向几个分区INSERT数据会大大降低INSERT性能
- 应尽可能以大批次INSERT,如一次INSERT 100000条数据
- 通过一个分区键分组后批量INSERT
- 性能不会下降的情况:
- 数据实时INSERT
- 数据按照时间排序INSERT
- 同时向几个分区INSERT数据会大大降低INSERT性能
- ……
把ClickHouse的文档翻了很多遍之后,我认为自己建表已经万无一失了。
建表的确是没问题,使用上有问题。数据是一批批上传到服务器,一条条落入数据库。
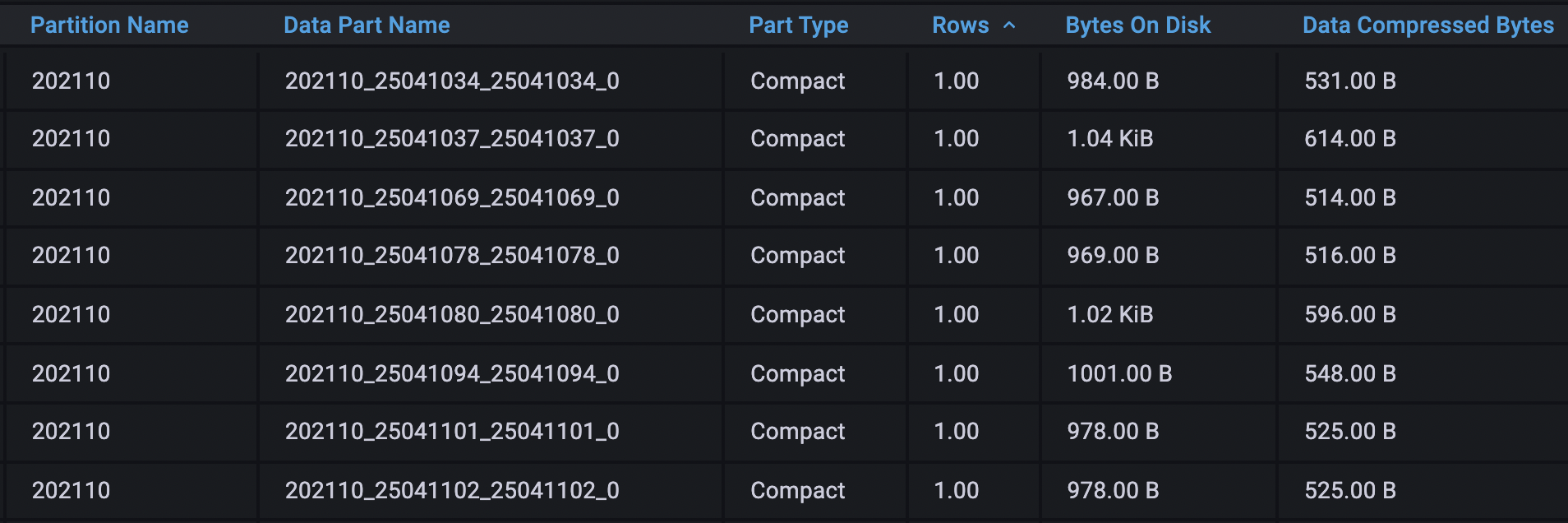
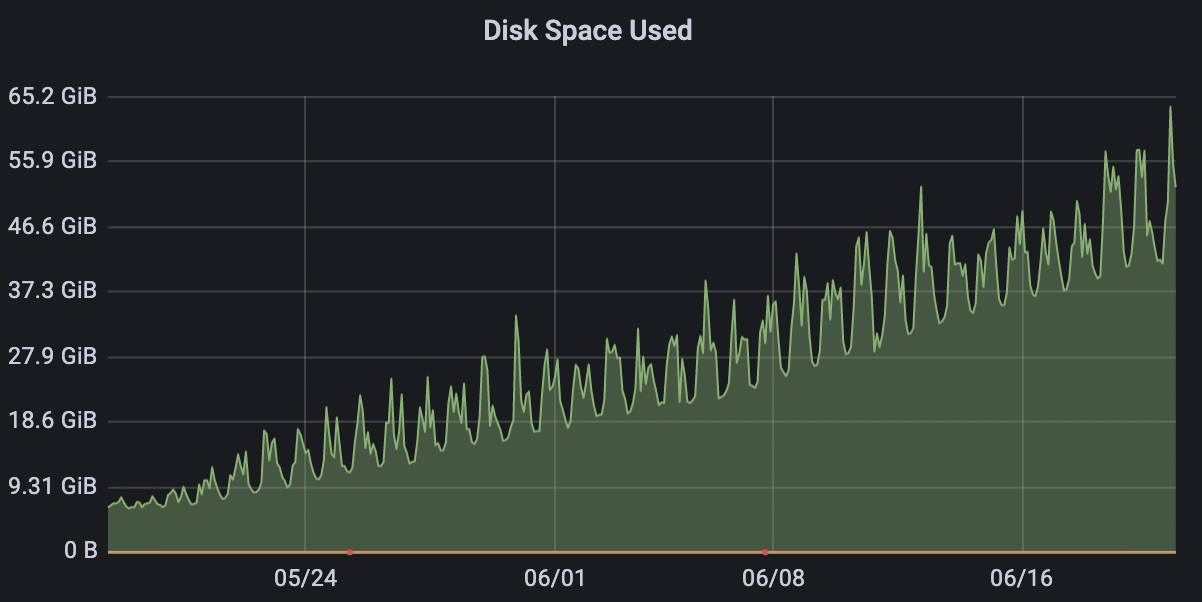
每一次INSERT操作会触发一次compact part生成,而1条数据和100条数据的大小并不是1:100,更大可能是1:4。单条数据源源不断流入数据库,磁盘空间占用会先大量增长,在大量compact part被慢慢合并成wide part后,磁盘空间又会慢慢吐出。
改进应用
增加每次INSERT的数据量
虽然数据实时INSERT不会引起性能下降,但磁盘用量有点夸张,早期忙时会先吃掉30G,闲时合并文件吐出27G,用户量上来之后磁盘占用起起落落就非常巨大。
为了将数据更能一批批而不是一条条落入数据库,lumberjack那边的KafkaListener我开始用batch mode,将一次从Kafka获取数据的时间放长,将这批数据合并送入数据库,尽可能增加一次INSERT的数据量以减少磁盘占用。
代码上从:
@KafkaListener
public void consume(String data) {
// process
}
改为:
@KafkaListener(containerFactory = "batchFactory") // define batchFactory befordhand
public void consume(List<String> data) {
// process
}
部署上线后效果并不明显,看概率:高峰时每秒数据量很多,但并不集中在某一秒或平均到每一秒上,闲时则没什么帮助,但是看着compact part时有20-100多的数据量,心里稍微有点安慰,因为我又节省了这次INSERT产生的90-99%的磁盘空间。
以Kotlin重写应用
进行数据处理时,有时候需要提取attr属性:
{
"a": {
"b": {
"c": {
"attr": "value"
}
}
}
}
在Java中,将该JSON反序列化回来后,要使用attr,需要进行级联判空,代码类似于:
SomeObj obj = objectMapper.readValue(json, SomeObj.class);
if (obj.getA() != null && obj.getA().getB() != null && obj.getA().getB().getC() != null) {
// handle attr
}
而Kotlin时中使用safe call,代码类似于:
val a = objectMapper.readValue<SomeObj>(json)
val v: String? = a?.b?.c?.attr
// handle attr
面对成篇判空的代码,换成Kotlin的时候safe call就很干净,加上Kotlin中万物可let/when/apply,代码写起来特别简练,管道式的写法让代码像可插拔的模块一样。于是我用Kotlin将原有项目重写了一遍。
不幸的是,Kotlin并没有想象中的那么完美,如重复注解(如多个@PropertySource)不支持,需要找支持重复注解的其他注解(如@PropertiesSource);注解中字段不是基础类型时需要显式指定类型;要写.class有时候需要动脑想是::class还是::class.java;用Jackson反序列化JSON时objectMapper.readValue<SomeObj>(json)的写法非常直观,但写完之后还要等IDE告诉我有错误,等待import com.fasterxml.jackson.module.kotlin.readValue提示点一下才能好;由于Kotlin类型后置,在IDE进行提示的时候CPU占用都会蹭的一下上去,写得稍微快一点CPU就35-50%的占用率,风扇呼呼转就算了,高速写代码时我还得时不时停一下等IDE缓过神来才能继续往下写。
写完之后上线,CPU占用率从峰值2.5%升高到了4.2%,看性能指标的时候我当时都傻了:

因为从Java切到Kotlin时,我把JVM的版本也从15切回8,GC也换掉了,也有可能是JVM的问题而不是Kotlin的问题更不可能是我的问题
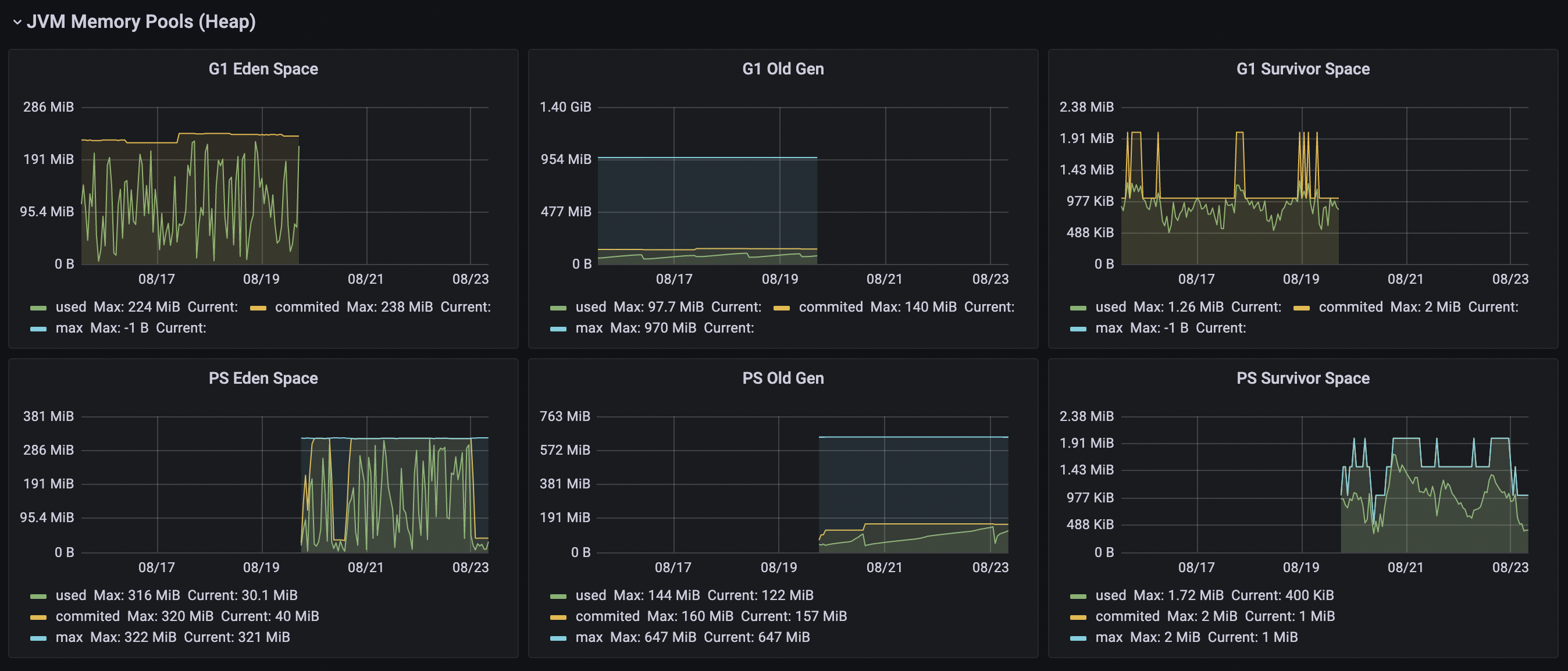
流量翻倍后,目前CPU的峰值为7.3%,性能近似线性;需要新增指标时,代码添加也很简单,只需要在流程中加一行代码,新增提取指标的方法,就好了,维护起来非常方便,往往是语音会议上我一边看着文档一边改代码,会议开完了我也正好能在需求文档上打钩,标记完成。
ClickHouse的特殊用途
后来一些需求都有点古怪,但都正好利用了ClickHouse的一些特性,做得又快又漂亮。
SummingMergeTree和统计
有个统计需求,统计每天的数据来源,但不需要关心每个时段的总和。
ClickHouse中的SummingMergeTree能够自动为相同Primary Key的数据进行聚合,插入同样Primary Key的数据就会自动续加一,于是有了这样的一个表:
CREATE TABLE source_stat
(
Country String,
Subdivision String,
City String,
Counter String,
CreateTime DateTime
) ENGINE = SummingMergeTree(Counter)
PARTITION BY toYYYYMMDD(CreateTime)
ORDER BY (Country, Subdivision, City, CreateTime);
这样就不需要跑报表,拉特定时间范围数据就能拉出结果:
| Country | Subdivision | City | Counter | CreateTime |
|---|---|---|---|---|
| Albania | Berat District | Berat | 1 | 2021-06-01 00:00:00 |
| Albania | Durrës District | Durrës | 1 | 2021-06-01 00:00:00 |
| … | … | … | … | … |
那如果需要每个时段的总和呢?也很简单,但这个问题要留给各位观众老爷想。
带TTL的表和统计
ClickHouse能够为表指定TTL(Time To Live),数据在表中超过存活时间后会自动删除,可以利用这个特性玩出很多花样。
如有个统计需求,需要统计消息到达用户那边之后,用户一天内会不会反馈,反馈需要多长时间。根据这样的需求,定制两张表:
CREATE TABLE record
(
Belong_To String,
Type String,
Interval_Minute UInt64,
...
CreateTime DateTime
) ENGINE = MergeTree
PARTITION BY toYYYYMM(CreateTime)
ORDER BY CreateTime;
CREATE TABLE record_tmp
(
Belong_To String,
Type String,
...
CreateTime DateTime
) ENGINE = MergeTree
PARTITION BY toYYYYMM(CreateTime)
ORDER BY CreateTime
TTL CreateTime + toIntervalDay(1);
消息发送时,先在record_tmp表中记录,消息确认之后,在record_tmp表中查找并计算Interval_Minute,接着落入record表中成为事实。
实际具体需求比这个要复杂一些,但同样需要看使用者的表现。
数据展示和报表统计
很早之前看到个说法,记录了下来:

但我使用Superset的时候,发现Superset是真心难用我组除了我都会用Superset,前几天我们组刚把Superset升级到最新版本,实际上就是我菜
比如他自带的driver对ClickHouse的支持很差,用时发现不支持LowCardinality(String):works wrong for specific clickhouse type LowCardinality(String) #58,需要手动升级;不支持sankey loop diagram,转化率和跳转图做得不够好,只能用sankey diagram做单向图,但看代码又有sankey loop diagram支持…我就搞了好长时间viz.py和viz_sip38.py往里面添加功能,结果性能很差,每次查的时候都能把浏览器搞爆,我就跑去用Grafana了
Grafana很好用,ClickHouse的查询从来没出现过奇怪的Bug,可以做这样高精度且清晰的图,可精细到街道:
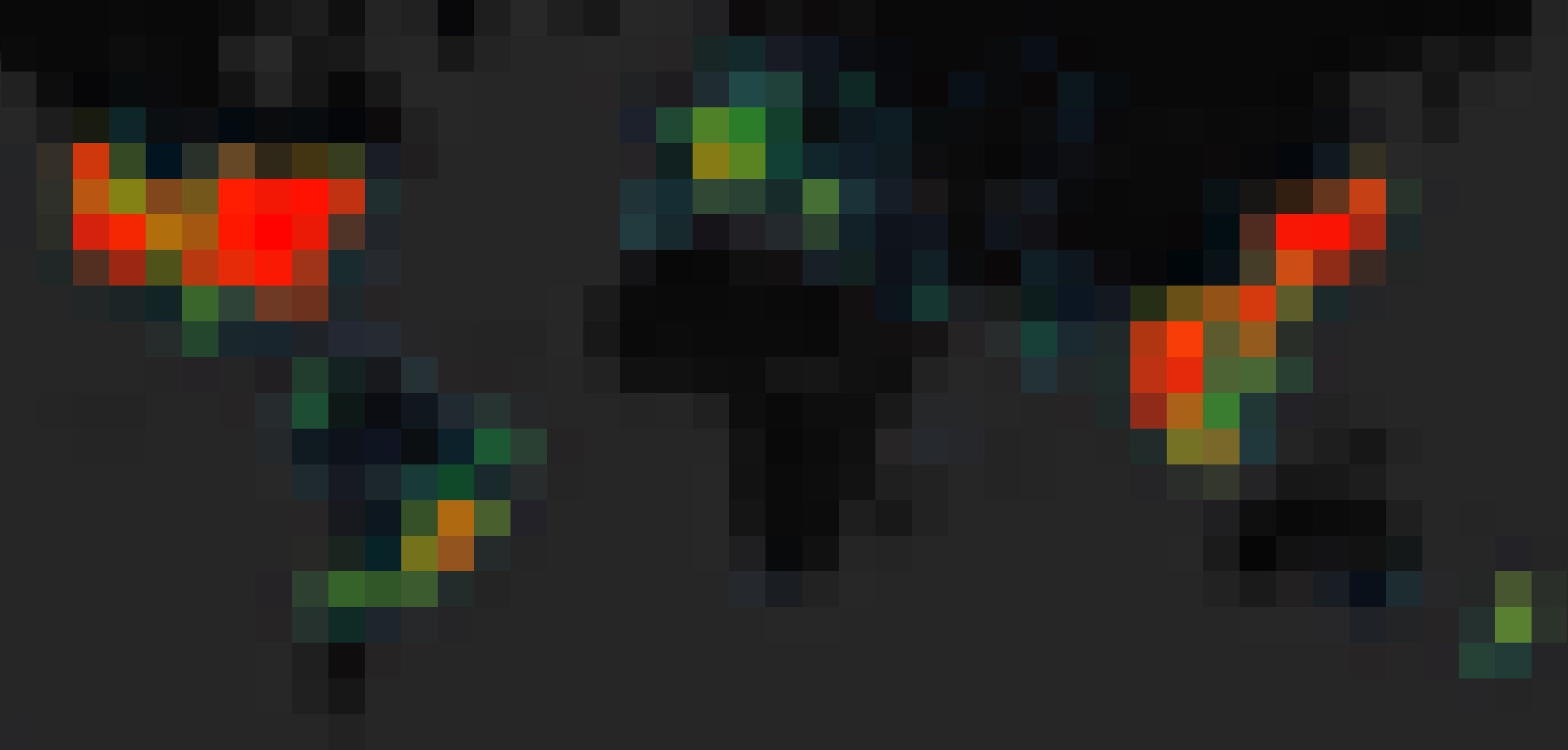
还有很方便的Copy和Duplicate功能,只要做好一个图表,直接复制粘贴改改里面的值就好了,开发效率很快。
当然也不是一帆风顺,我们一起做Dashboard时经常发现某个图表没问题,升级后有问题,再升级就没问题,或是反过来:如我们在今年7月21日,在用7.X版本的饼图,一切正常,升级到8.0.0版本之后,比较少的数据量就会导致整个饼图数据不正常,再升级到8.0.6,就好了,但是其他图又挂了。实际上就是升级了版本之后出问题,如果不升就不会有问题。
后来我们碰到Grafana问题解决思路是:
- 有没有新版本:
- 有:升级,看问题还存不存在
- 有:去Issues列表看看有没有人有同样问题,他们怎么解决
- 有:根据他们的办法解决
- 没有:等新版本或上RC版本,只要你敢出我就敢用
- 没有:好耶
- 有:去Issues列表看看有没有人有同样问题,他们怎么解决
- 没有:去Issues列表看看有没有人有同样问题,他们怎么解决
- 有:根据他们的办法解决
- 没有:等新版本或上RC版本,只要你敢出我就敢用
- 有:升级,看问题还存不存在
也有解决不了的问题,比如现在我们在用Grafana 8.1.3版本,有个Bar Gauge从8.0.0开始就一直不正常:
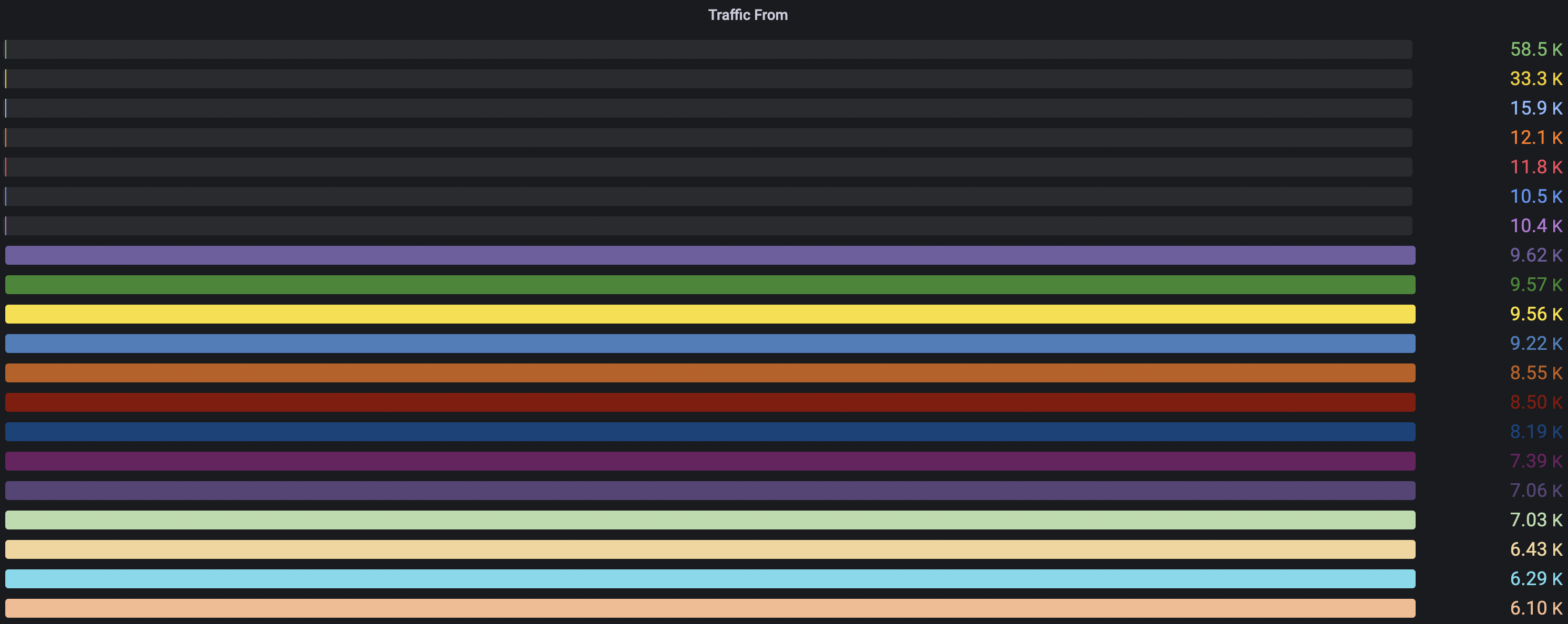
问题根源是:Panel无法为Max Value设置一个合理的值。将Max Value手动设置为65000时,这个图表就正常了:
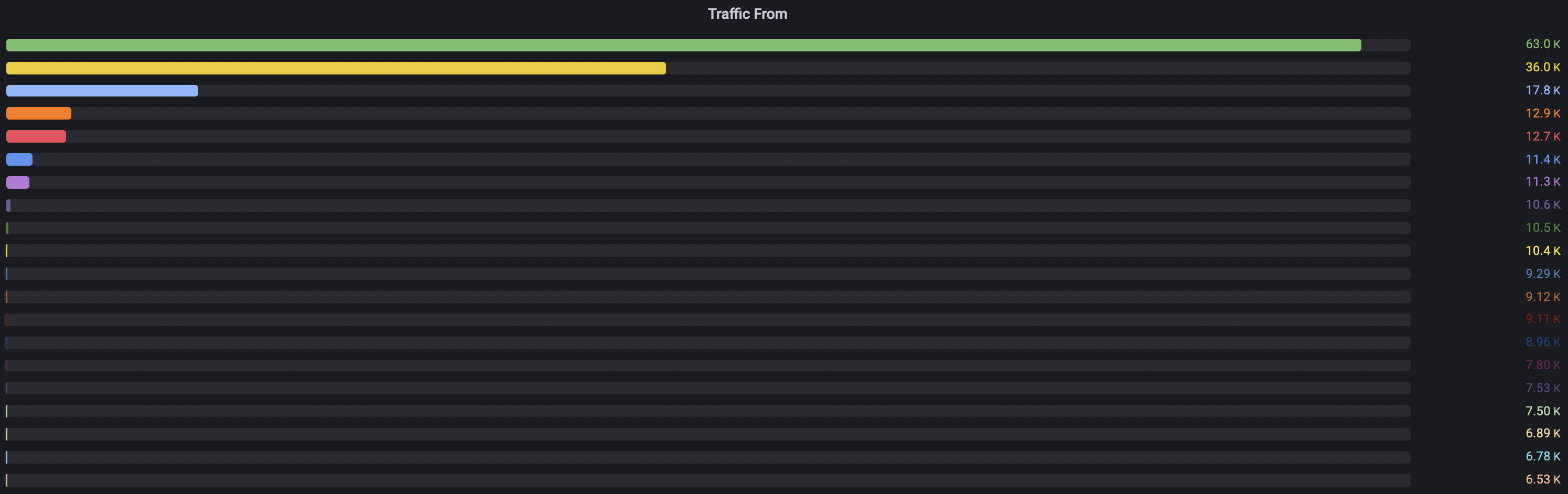
但是我统计时间范围只要一扩大,排名第一的数值超过65000,那这个图表又开始不正常了…看了一眼Grafana出了8.2.2版本,明天再升级看看
ClickHouse明明很强大但过度谨慎
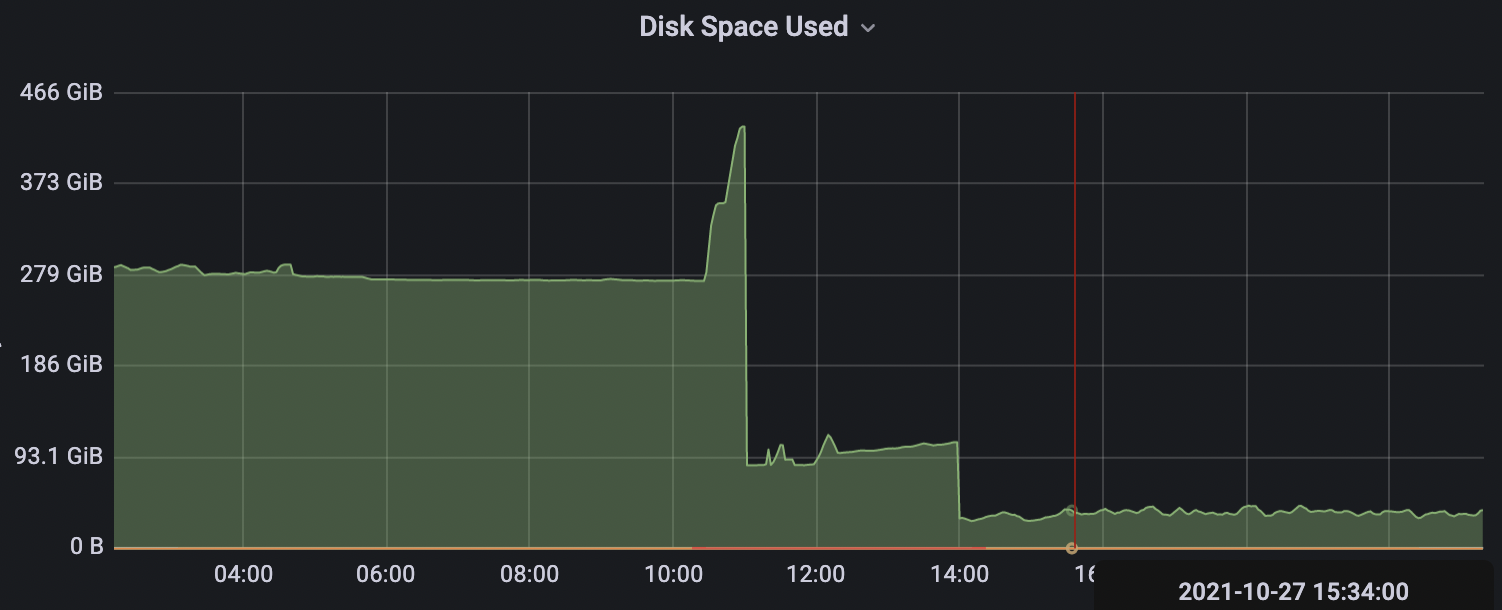
前面提到了ClickHouse的磁盘占用问题,按照上面数据增长图表来看,在中国的春节期间,所有数据中心ClickHouse的磁盘正好吃满,而我在进行ALTER TABLE DELETE操作的时候,发现表空间竟然是缓慢释放…急的时候真的是不行,还得想办法解决这个问题。
好在ClickHouse也有RENAME,上面的架构正好提供任意时段维护ClickHouse的手段:
- 将lumberjack应用关掉,此时不会有数据流入ClickHouse
- lumberjack应用关闭不影响chainsaw接受数据,因为数据被缓冲在Kafka里
- 维护好ClickHouse之后,打开lumberjack消费Kafka中的数据
- 避开job定时任务开跑的时间
重新整理数据表,则可以将原表数据导入到新表:
- 如需要整理A表,则可以新建一个同构的A_TMP表
- 将A表数据导入A_TMP表
- 将A表RENAME为A_OLD
- 将A_TMP表RENAME为A表
- 将A_OLD表删掉
通过这样的指令,将大部分磁盘占用归还回来。
心得
写这文章发现了没开启ClickHouse的async insert,开启这个选项能够让ClickHouse帮忙合并数据减少INSERT次数,学无止境,常学常新。
文章构思于2021年10月29日凌晨0点到3点,晚上ClickHouse的群组置顶了一条信息,让我回想起使用ClickHouse的经历,真是一段快乐的时光。
